【中译】无人在意的 RAXXER 的“Vocaloid 数据库文档”没用附加内容
你好! 我是 RAXXER,也可以叫我 Razer 或 Crazer。这篇文章会介绍一些可以为声库做的额外小技巧。
在继续往下看之前,强烈建议先去阅读 #tools-and-utilities 频道里的声库制作指南。
无论如何,这份文档都不会消失。需要帮助的话,请在 Discord 上联系我:razer_rhela
EpR 估计
EpR可以指 Excitation Plus Resonances(激励加共振),或者Estimated Pitch Range(估计音高范围),这里我们取后者。如果你熟悉 RVC,可以把它当成是索引文件。它不是必须的,但确实能明显提升声库的音质。
EpR 背后的原理我不精通,但我可以教该怎么设置它!
对比有无 EpR 估计模板的声库:
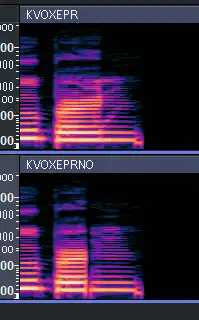
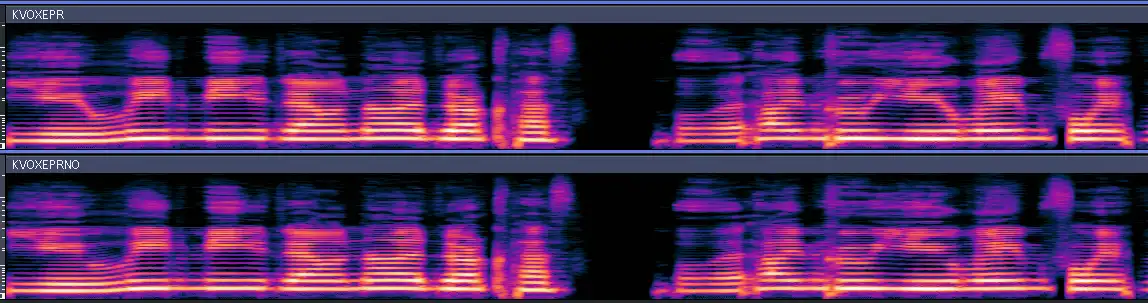
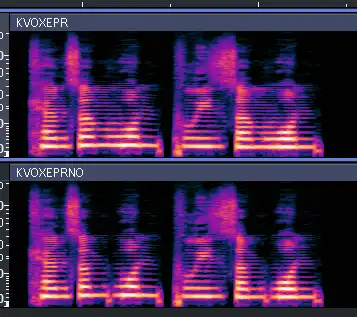
信了吧?齿擦音上的效果最明显,音与音之间的过渡也会顺畅很多。
嗯,那现在该怎么办?
你已经动手做声库了?那正好!现在你可以把大部分工作都扔掉!
开玩笑的。如果只做了初步分段,那直接新建文件夹重开就好,旧的分段文件还可以继续用。如果你做了很多……那我只能替你心疼一下了。
如果你用的是 DaisyAnnotationTool 来分段,那可以继续做完,不过 stationary 这一步请改用 VocaloidDBTool3 来做。
词典
在重建声库文件夹之前,要确保你的词典末尾已经加上了 EpR 模板:
template(phoneme="*"):
000.000000, 0.000000
0000.000000, 000.000000
0000.000000, 00.000000
0000.000000, 0.000000
在最上面加上:
default_epr_resonances_templates:
template(phoneme="ER"): ## 激励共振
200, 200 ## 250, 350
0, 0
0, 0
0, 0
把 * 换成你的元音……最后应该像这样:
default_epr_resonances_templates:
template(phoneme="ER"): ## 激励共振
200, 200 ## 250, 350
0, 0
0, 0
0, 0
template(phoneme="a"):
700, 0
1350, 100
2750, 100
3700, 0
template(phoneme="e"):
700, 0
1350, 100
2750, 100
3700, 0
template(phoneme="i"):
700, 0
1350, 100
2750, 100
3700, 0
依此类推……
注意开头必须是
default_epr_resonances_templates。
词典里的默认数字可以留着不管。如果你想自己添加,可以查看 自定义 EpR 模板 ,这部分是独立于词典的。
设置 STA
要让 EpR 发挥最大效果,需要把 stationary 录音拼接起来。这个做法在工具包的一份西班牙语文档里也出现过。
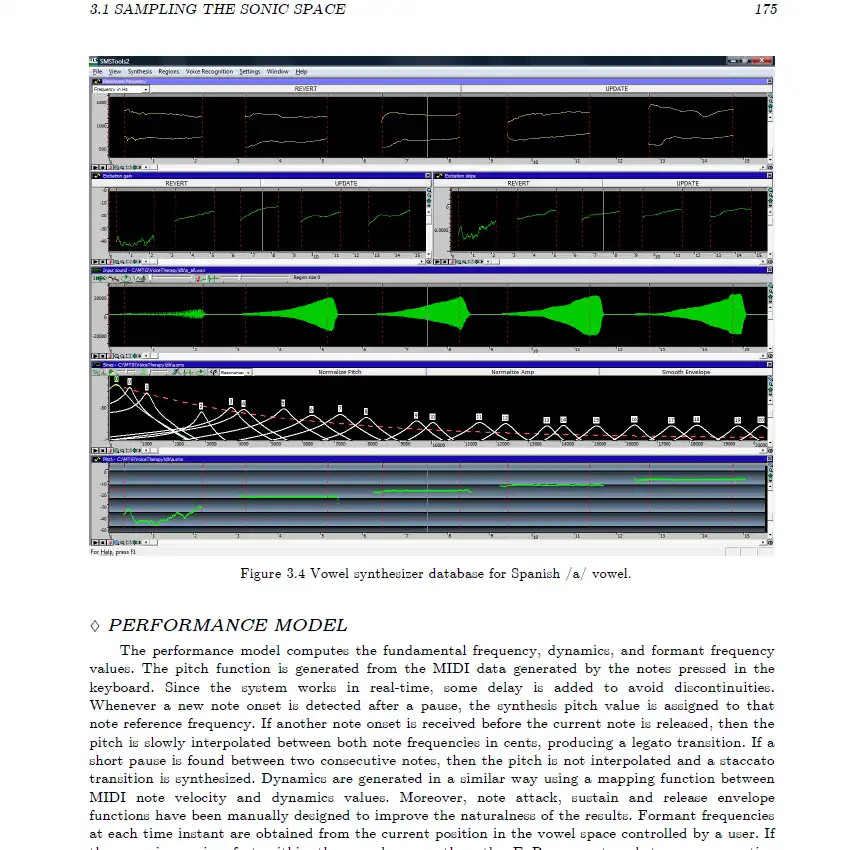
说白了,就是把同一元音的所有 stationary 按音高从低到高拼成一条。*
- 顺序可能无所谓,但这么排最清爽。
 ↓
↓

上面是 [a] 的例子,其他元音同理。辅音的 EpR 估计会基于你常规的配置(据我所知)。
分段
现在是最轻松的一步。如果你以前做过声库,现在只想加上 EpR 模板,那就把 .wav、.seg 和 .trans 文件拿过来用,注意不要混进旧的 stationary。为你的 stationary 新建空白的 .trans 文件。
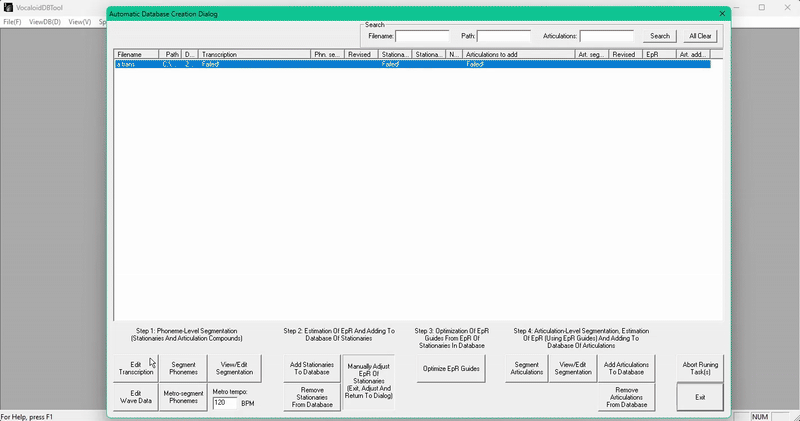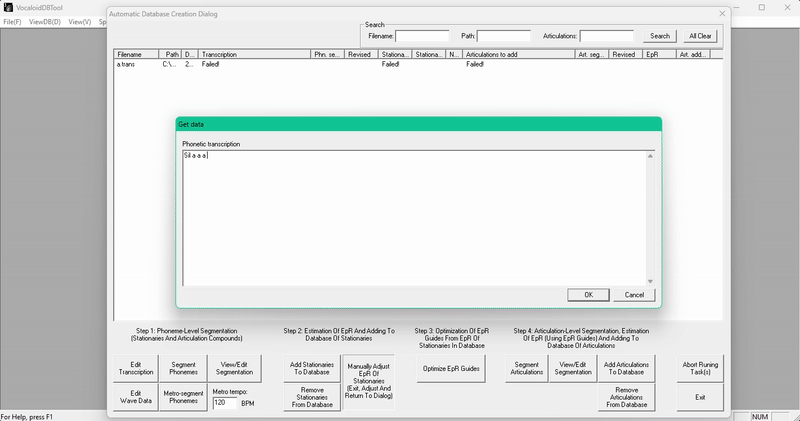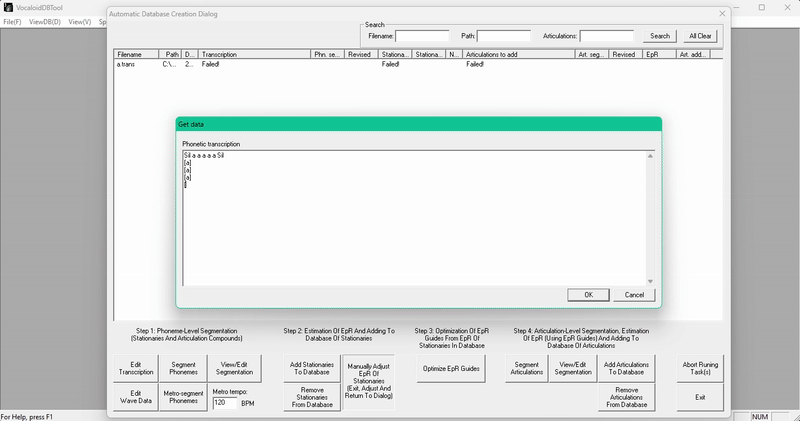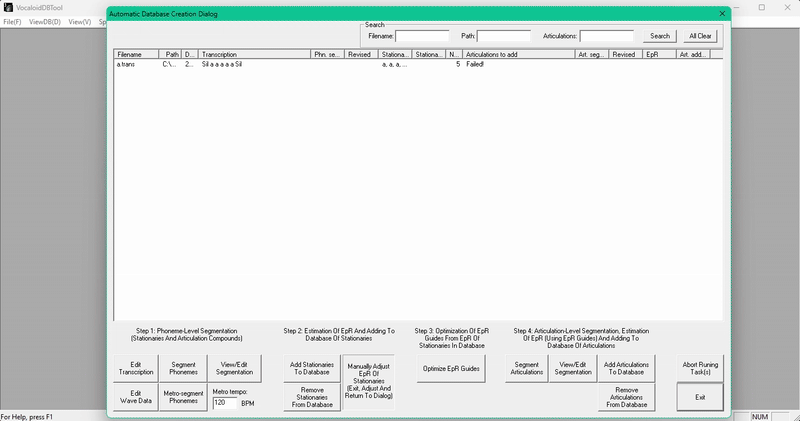
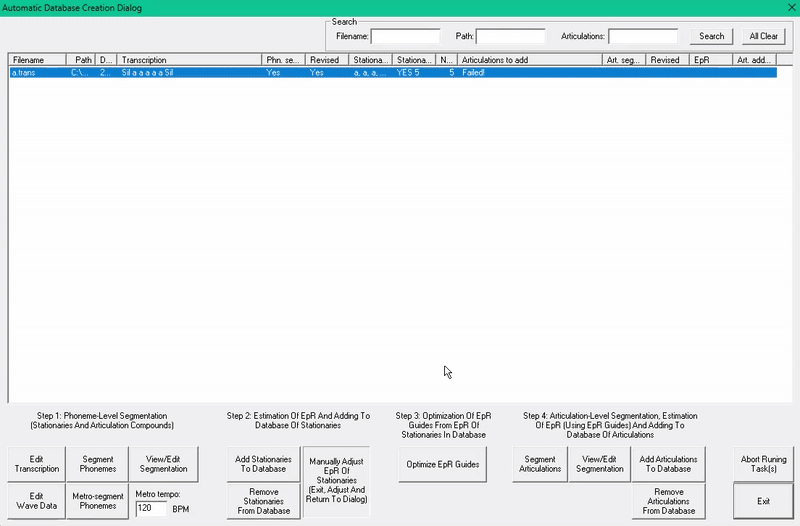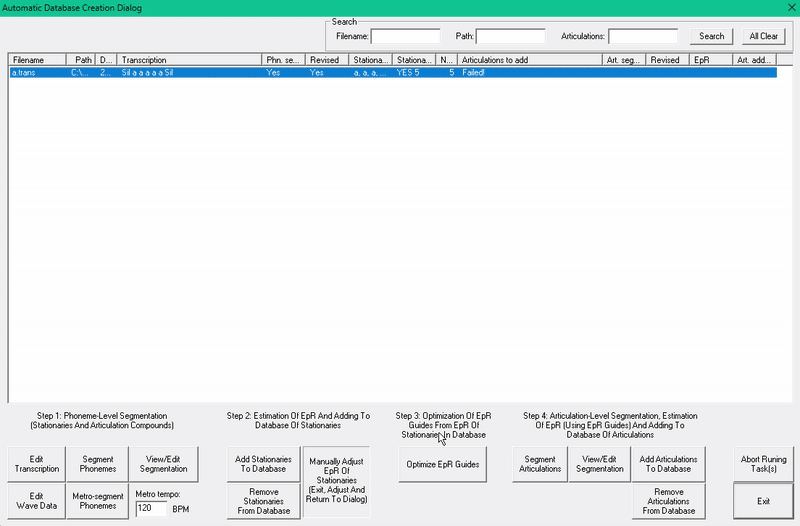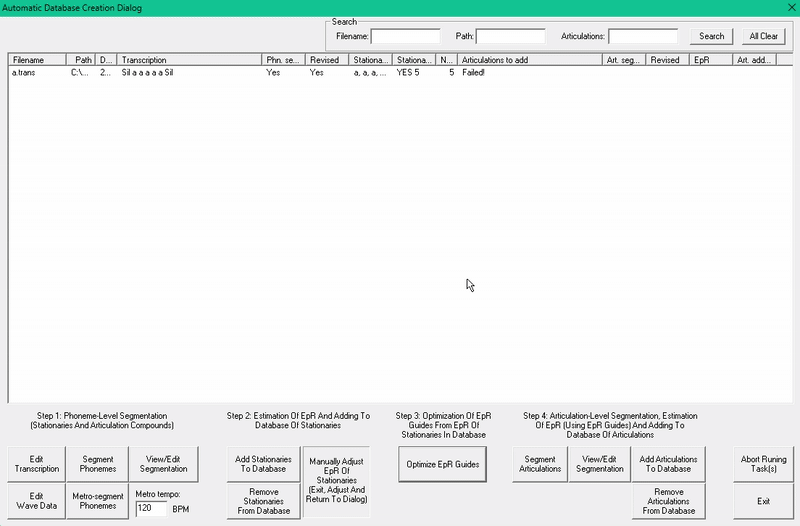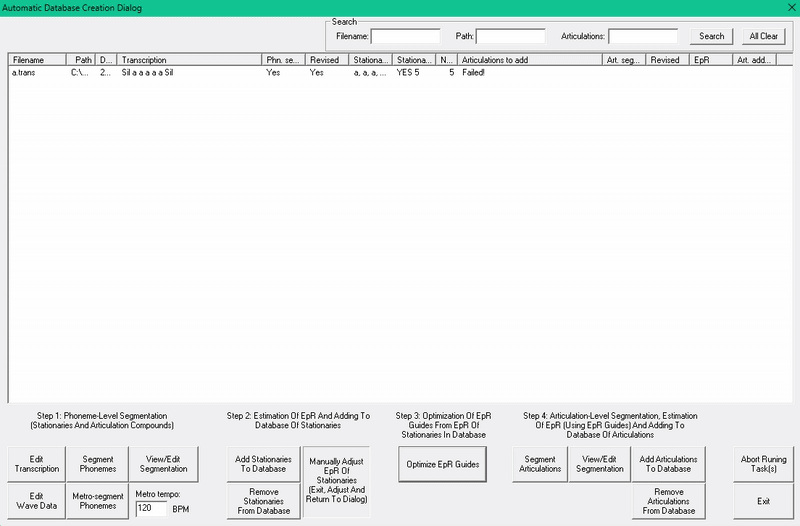
新建一个声库文件夹,选择加了 EpR 模板的词典,然后打开 Automatic Segmentation(自动分段)。
为了方便整理,我把 STA 的 wav 放在单独的文件夹里,你不必非得这么做。
点击 Edit Transcription(编辑转录),根据拼接在一起的音高数量填写音素数量。我这里一共 5 个。
然后像平常一样配置你的 stationary!
像往常一样把 stationary 添加到数据库里,这一步可能会比平时多花一点时间。
(可选)如果你想自己指定 EpR 的数值,参见 自定义 EpR 模板。然后跳过本节剩余部分。
接着点击 Optimize EpR Guides(优化 EpR 指南) …… 见证奇迹的时刻!!!!!!(并不)
什么都没发生……?这其实是好事,没想到吧?
如果你配置了不止一个 stationary,就会弹出一个进度条。

确认它真的干活了
进到你新建的声库文件夹里,会看到一个叫 epr_templates.txt 的文件,里面应该已经填好内容了。
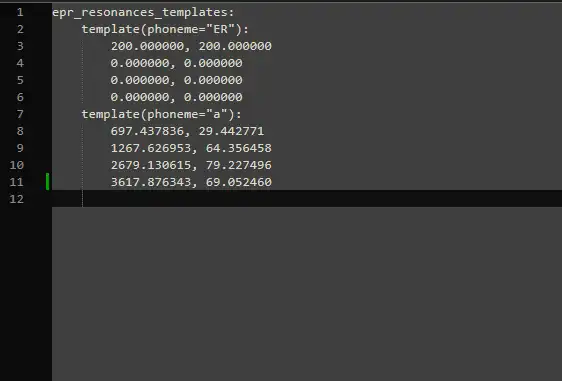
完事。把剩下的声库文件加回去,再切一下辅音,你就得到了属于你自己的 EpR,大家会夸你的。
报错
无法估计第一帧和/或最后一帧的 EpR

要么是切的位置太近了,要么是你在 EpR 字符串前面(或上面)不小心打了制表符(一般是按 Tab 键出来的)。
以下 stationary 的手动 EpR 估计在不同音高上可能不一致
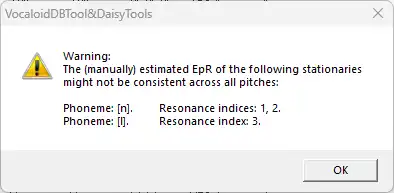
系统读不出音高线,不过这个影响不大。
自定义 EpR 模板
使用 PRAAT 来修改默认数值。
你可能注意到了,stationary 那一步旁边有这么一行字 
我们就在这一步里操作。建议装上 PRAAT,除非你有其他能分析共振峰和带宽的工具。先把 automatic segmentation(自动分段) 关掉。
应该有一个叫 epr_templates.txt 的文件,里面就是词典自带的默认数值。
把它打开,放一边。然后打开 Praat。
通过 Open(打开) > Read from File(从文件读取) 或 Open(打开) > Open Long Sound File(打开长声音文件) 打开你之前拼接好的 stationary,会弹出一个显示 wav 文件的窗口。
选中你要看的那条,再点 View and Edit(查看和编辑),会新开一个窗口显示波形。记得放大一点,能看到窗口底部。
现在,随便选一个 stationary。根据我的测试,选哪个音高都行,不过我个人习惯选声库里听起来最自然的那个音高。
拖拽鼠标选中整个 stationary,别点丢了。
然后切到 formants(共振峰) 选项卡,点 Show formants(显示共振峰)。往下翻一点,你应该会看到四个共振峰以及对应的带宽——这些就是我们要的数据。
按快捷键 F1,或者手动点一下,会弹出一个窗口显示具体数值。现在我们回头看 epr_templates.txt,里面的一条记录大概长这样:
template(phoneme="a"):
790.000000, 10.000000
1300.000000, 70.000000
2800.000000, 50.000000
3760.000000, 0.000000
逗号前是共振峰(Formants),逗号后是带宽(Bands)。有了这些信息就可以去填 epr_templates.txt 了。比如,第一个共振峰是 1095.4409956453749,对应的带宽是 105.60436272944551。你只需要小数点前的整数,填成下面这样:
template(phoneme="a"):
1095.000000, 105.000000
1300.000000, 70.000000
2800.000000, 50.000000
3760.000000, 0.000000
其他共振峰和带宽也照此处理,最后结果大概是这样:
template(phoneme="a"):
1095.000000, 105.000000
1509.000000, 63.000000
2711.000000, 71.000000
3634.000000, 102.000000
对其余的 stationary 重复上面的步骤。全部做完后,回到自动分段,在第三步点 Optimize EpR Guides(优化 EpR 指南)。
你原来的 epr_templates.txt 会被替换掉,系统会根据你填的初始值再做一次优化。之后就可以继续正常的声库制作流程了。
跟直接使用默认数值比起来,差别大吗?
其实不大,这部分还需要更多测试。
LSF(线谱频率)
点击 Compute LSF(remake EpR)会搞乱多个参数设置。
点击 Compute LSF(Keep EpR)则会破坏 v4dev,而且编译时直接崩溃。
稳定标记(循环区域)
你可以调整 CV 的循环起点,让 stationary 放在采样最稳定的部分。实际上 stationary 并不会把 CV 拉长,它们只是帮忙给采样做共振峰处理(如果我没记错的话)。待施工。
phn_seg.py
phn_seg.py 是开发套件用来估计音素位置的脚本。点击 Segment phonemes 时调用的就是它。它是根据音量大小来估算音素边界的。如果你在用 DaisyAnnotationTool,那基本用不上这个。
可以在某个群里搜一下这个文件,应该能找到。
如果你按照原始文档操作过,那应该已经装好了 Python 3.10。
在 VocaloidDBTool3.exe 所在的文件夹里,新建一个叫 scripts 的文件夹。
把 phn_seg.py 放进去。
打开分段工具时,记得选中 VocaloidDBTool3.exe 所在的文件夹,然后点“分段音素”,它就会自动运行。
注意,因为是基于 Python 的,声库文件夹的路径里不要有空格。
提醒一下,它是根据采样的音量来设置音素边界的…… 肯定不是百分百准,但也还算好用。
开发套件提到还可以“metro-segment”音素,理论上需要另一个 .py 文件,但我们并没有那个 :[
顺带安利一下 KVOX