【中译】Vocaloid声库制作教程
译注:本文为该文档中文精翻,仅供学习参考使用,内容及立场不代表译者观点。
文章内容相关问题请咨询原作者。复现文章内容造成一切后果,均与译者无关。
原文地址原文地址
前言
请勿转载
警告
创建Vocaloid声库需要时间与耐心,目前没有任何捷径或例外。
如果您没有足够的时间、耐心或电脑空间(5GB以上),最好不要尝试。

请不要尝试利用“资源”中的信息或工具牟利。
Vocaloid声库制作教程
逐步制作Vocaloid3-5声库的指南。
※本指南会持续更新、修正并添加信息。如遇页面维护中断,敬请耐心等待,通常表示文档正在编辑中。
译注:此处指原文,本翻译不保证更新及时。
作者:daigasso
常见问题
遇到问题了吗?请务必仔细阅读所有内容!记得查看常见问题部分。 仍然遇到问题?加入 Discord 服务器获取支持和/或与其他开发者交流。【目前仅接受申请加入】

问:这很难吗?
答:Vocaloid本质上就是一个更强大的UTAU或DeepVocal。在开始之前,您应该至少了解制作UTAU声库的基础知识。如果您不熟悉这些内容,可能会遇到困难。
问:可以制作V6AI吗?可以在正版Vocaloid中使用吗
答:不行(至少V6不行,但可以在正版中使用)。 如果您想做AI声库,请选择Diffsinger或者NNSVS。目前不支持V2,因为格式与结构不同(在ddi结构上存在差异)。
问:选CVVC还是VCV?
答:如果您打算制作VCV,最好在CVVC的基础上制作。虽然也可以直接制作,但转录音素时需要注意进行优化。这取决于您。
※例:英语4/dx音标可能需要VCV才能流畅运行。
问:我制作了不同的音阶,但我不知道它们怎么起作用?
答:Vocaloid的音高系统是基于频率的。音高后缀无关紧要,但要注意高音区。高音区可能会主导声库。因此,您应该把假声等采样放在单独的声库里,或者用特殊的音素标记。
问:应该在标记之前对采样降噪吗?
答:这完全是个好主意,只需在将采样添加到声库之前清理它们即可。
问:所有的采样都是必要的吗?
答:的,它们都是必需的。没有其他办法。您要么录制全部采样,要么就手动编辑音素。Vocaloid的设计非常特殊!
问:DBTool崩溃了怎么办?
答:DevKit会实时保存编辑,只需重启即可。
问:可以移植UTAU声库吗?
答:可以。只要它不是CV格式的。移植到Vocaloid后会不会有点怪?有可能。
问:应该在外置存储中操作吗?
答:Vocaloid的开发文件大小可能从1GB到20GB不等!而且这还是开发版本的大小,您应该在外部驱动器上工作。
问:没有自制字典怎么办?
答:可以从下方下载一个,或者自己构建一个。Vocaloid只支持它支持的语言,但这并不妨碍您以任何您想要的方式添加音素。注意,不要为V4添加C/V_0,它们会自动正常工作。您所要做的就是按音素输入。
※建议: 不要使用DevKit中默认的字典,它们可能存在音素缺失或其他错误,例如音素分类不正确。请使用“资源”中链接的字典集合。
问:为什么-不起作用?
答:确保已经具备所有的Stationary和openings。除此之外,我想不出其他原因。
译注:原文如此,不知道这里的openings是什么。
问:声库能在Piapro v4x中使用吗?
答:可以。所有三个版本,包括独立版、合法 VSTi 和 FE 版,都可以使用。对于 FE 版,您可以像在 V4 FE Plus 中一样加载它们。您甚至可以为它们添加自定义图标!(※请注意,合法支持更难实现,如果您不确定如何操作,请使用 FE 版。切勿冒险。Vocaloid 非常敏感,稍有不慎就会出错。)
问:使用某个音素时会听到奇怪的噪音?
答:标记位置错误!Vocaloid 对错误非常敏感。DevKit虽然是连续标记的,但您仍然需要正确放置标记。或者它们存在音高错误。在主窗口中,使用 Ctrl+单击来修正样本的音高。Ctrl+D+单击来删除音高。尤其要注意的是,如果辅音没有显示,请在其下方添加音高。
问:声库能在Tunelab中使用吗?
答:正确安装后,一切皆有可能。(也就是说,当安装程序以管理员身份运行时,它会自动注册,无需密钥。注意避免 compID 冲突!)
问:我可以分享我的声库吗?
答:可以,随VVD、CompID一起分享,其他人就可以毫无问题地使用它。如果分享了安装程序,就可以在tunelab中使用它!把它当作UTAU声库看待即可。但请确保您谨慎行事,并不要称其为官方版本!
问:我可以使用人力声库或RVC吗?
答:不建议这样做。
问:声库编译器错误-9和-1是什么意思?
答:-9是分段错误,应该出现在配置不完整或者没有正确适当的完成时。-1表示音频格式错误。
问:N\是怎么回事?
答:请了解 Vocaloid 中每种语言的音标映射。N\ 只是众多以“N”开头的音素之一。
问:?起作用吗?
答:它们用于表示喉塞音。通常 Vocaloid 声库会将它们归类为“喉塞音”。比如Steppu中,?就是e和pu中间的p。
问:配置中显示BAD是什么意思?
答:采样标记有重复或者音素不在字典中。也可能是转写错误。请记住,DBTool 比较挑剔,请谨慎使用,并确保操作尽可能规范。
问:Vocaloid中的音高怎么了?
答:和常规音高相比差了 1 级,例如,Vocaloid 中的 C4 是 C3。
问:开发版编辑器检测不到我的声库?
答:请确保两个路径都正确。唯一的区别是其中一个路径末尾应该有“.tree”。名称要简短明了,不要用英文句号,用下划线代替。
问:如何创建EVEC?
答:使用 Special 中的字典编辑器添加更多元音(实际标记为Change Phonetic Unit Group(更改音位单元组)),然后继续操作。
问:如何创建 XSY 预设,或者一般的预设?
答:使用声库编辑器导出它们,并在发布时将其添加到声库中。
问:如果我的Component ID重复了怎么办?
答:再创建一个。最好是自己编写。
问:我需要使用基于单词的录音表吗?
答:不需要!Vocaloid 的声音提供者们还不习惯音拍(mora)系统。您可以随意使用任何您想要的录音表。只要它包含您需要的音素就行。
问:这些音在我正在制作的语言中并不常见,我该怎么办?
答:没关系,录下来然后添加。不要漏掉任何音素/音节。
问:为什么不直接用 CV 呢?
答:Arsloid,就是这样。玩笑归玩笑,Vocaloid 仅靠 CV 是无法使用的。它在声库格式方面远不如 UTAU 那样灵活。
文件夹准备
这个过程与制作 UTAU 声库非常相似。基本步骤如下:规划音阶,创建文件夹,然后将采样添加到相应文件夹中。最多支持创建 11 个音阶,避免超过这个数量。
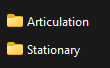
Vocaloid 使用Stationary和Articulation。Stationary采样有助于声库在音符中间保持音高。您可以将其理解为长元音采样。Articulation可以是 CV、CVVC、VCV 等。更专业地说,Articulation存储的是音素之间的衔接段。
采样数量没有限制;音频处理、通过 DAW 进行后期处理、模仿声音等都可以。
简而言之:
- 新建文件夹(声库名称);
- 音阶文件夹(如有,制作单音阶声库也可以);
Articulation/Stationary文件夹。
※注:DBTool 可以读取子文件夹。文件夹名称并不重要,纯粹是为了方便整理。
※以上截图中的“N_”代表“正常”,并非强制命名要求。
※音频格式很重要!无论如何,音频格式始终相同,即44.1kHz、16位、单声道、`.wav`格式。
什么是Articulation/Stationary?
更详细的解释:
Stationary,或称循环采样,是指在编辑器中用于延长音符循环播放的采样,Vocaloid 的音色主要来源于此。实际上,Stationary并不总是局限于元音,有时也包含辅音,例如 N 或英语中的 L。`Stationary`在制作中至关重要,不容省略。
※ 例:对于日语,Stationary通常包含:a、i、u、e、o、n。

Articulation,或称衔接采样,是指的元音与辅音衔接处的采样。Articulation没有限制,您可以完全自主优化。这意味着您可以添加CV、VC,甚至是CCV采样。简单来说,它们就是UTAU中的CV、CVVC、VCV等。
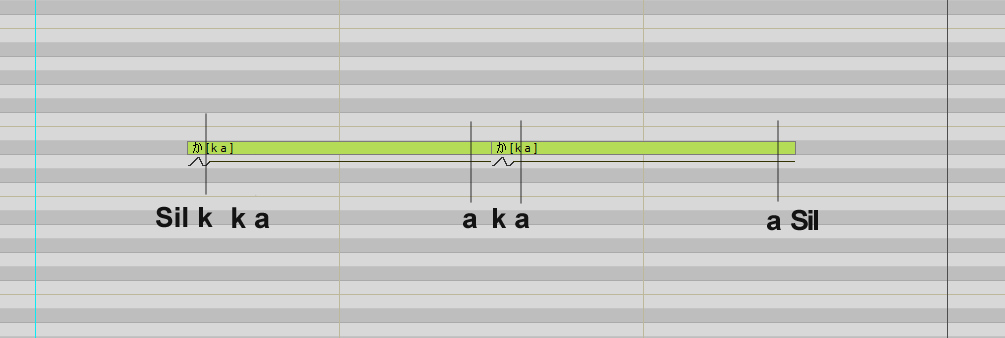
转录
顾名思义,转录就是将音频文件转录成文本。它们是扩展名为.trans的文本文件。请务必确保转录文件与其对应的音频文件同名,并位于同一文件夹中。每个音高的每个音频文件都需要一对转录文件。它们类似于 UTAU 的别名功能。
换句话说,转录文件用于指定音频样本的内容以及应该从中提取哪些音素。
以下是转录音频文件的示例。

- 假设需要转录
_b_ey_b_ey_b_k_ey_b-.wav。 - 您需要创建一个名为
_b_ey_b_ey_b_k_ey_b-.trans的文件,使用Windows自带的记事本或Notepad++打开此文件。 - 通常使用x-sampa音标来转录,但并非必须。您也可以使用其他音标,例如arpa。
- 在转录文件中,
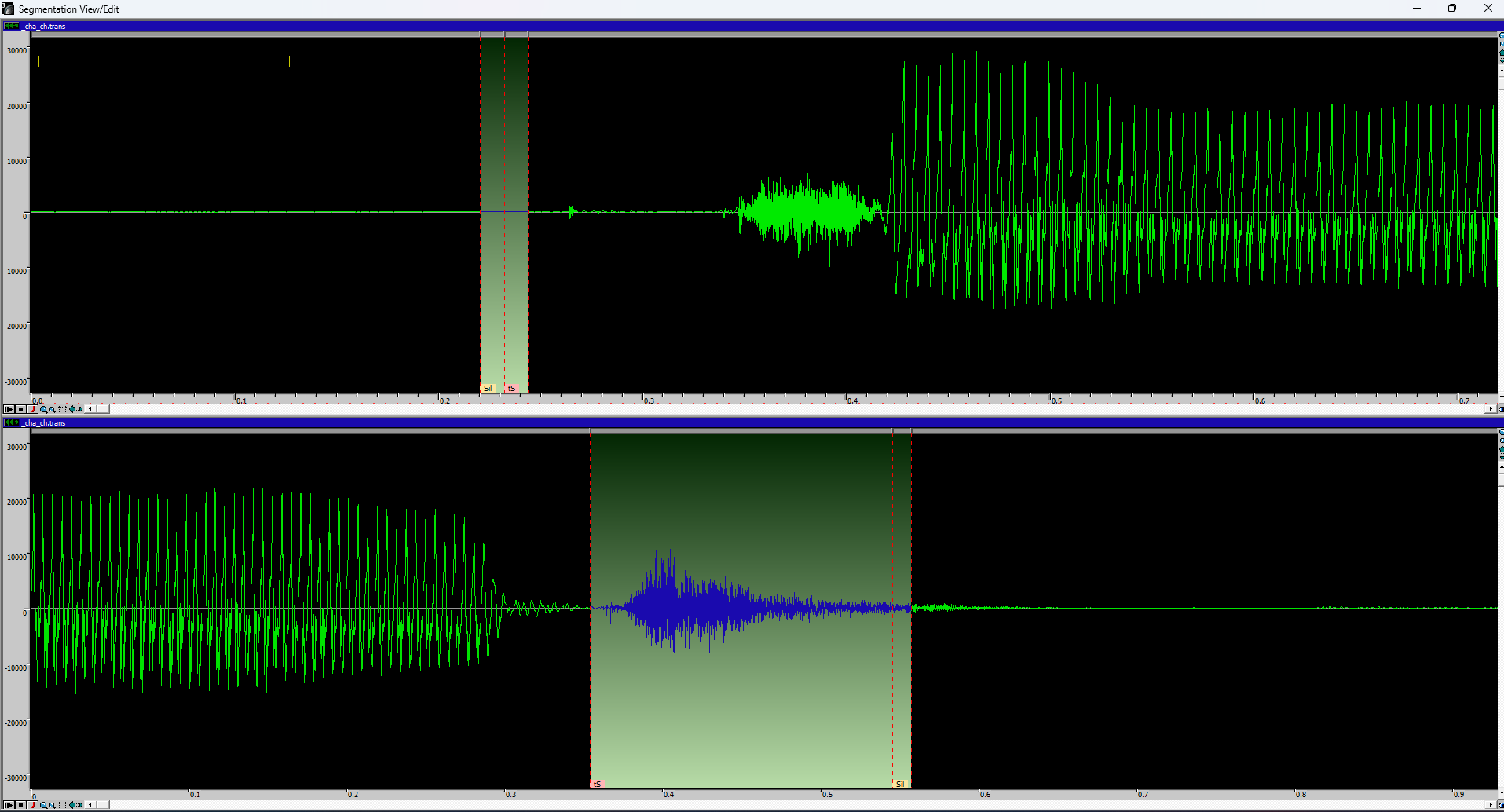
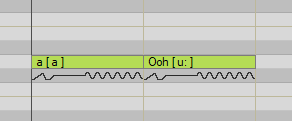
b ey b ey b k ey b被转换成一行文本Sil bh eI b eI bh kh eI b Sil。(Sil 是 silence 的缩写,可以在编辑器中使用) - 在下方使用方括号划分出想要从该行提取的音频片段,如
[Sil bh ey][ey b]等。下图是一个参考示例。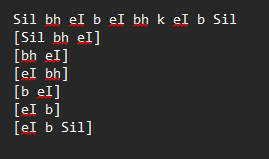
※ 注意:Articulation允许每个括号内包含多个音素,而Stationary的每个括号内只允许包含一个音素。请参考示例图片。
- 假设需要从
_a_i_u_e_o.wav中转录Stationary。 - 您需要创建一个名为
_a_i_u_e_o.trans的文件。 - 通常使用x-sampa音标来转录,但并非必须。您也可以使用其他音标,例如arpa。
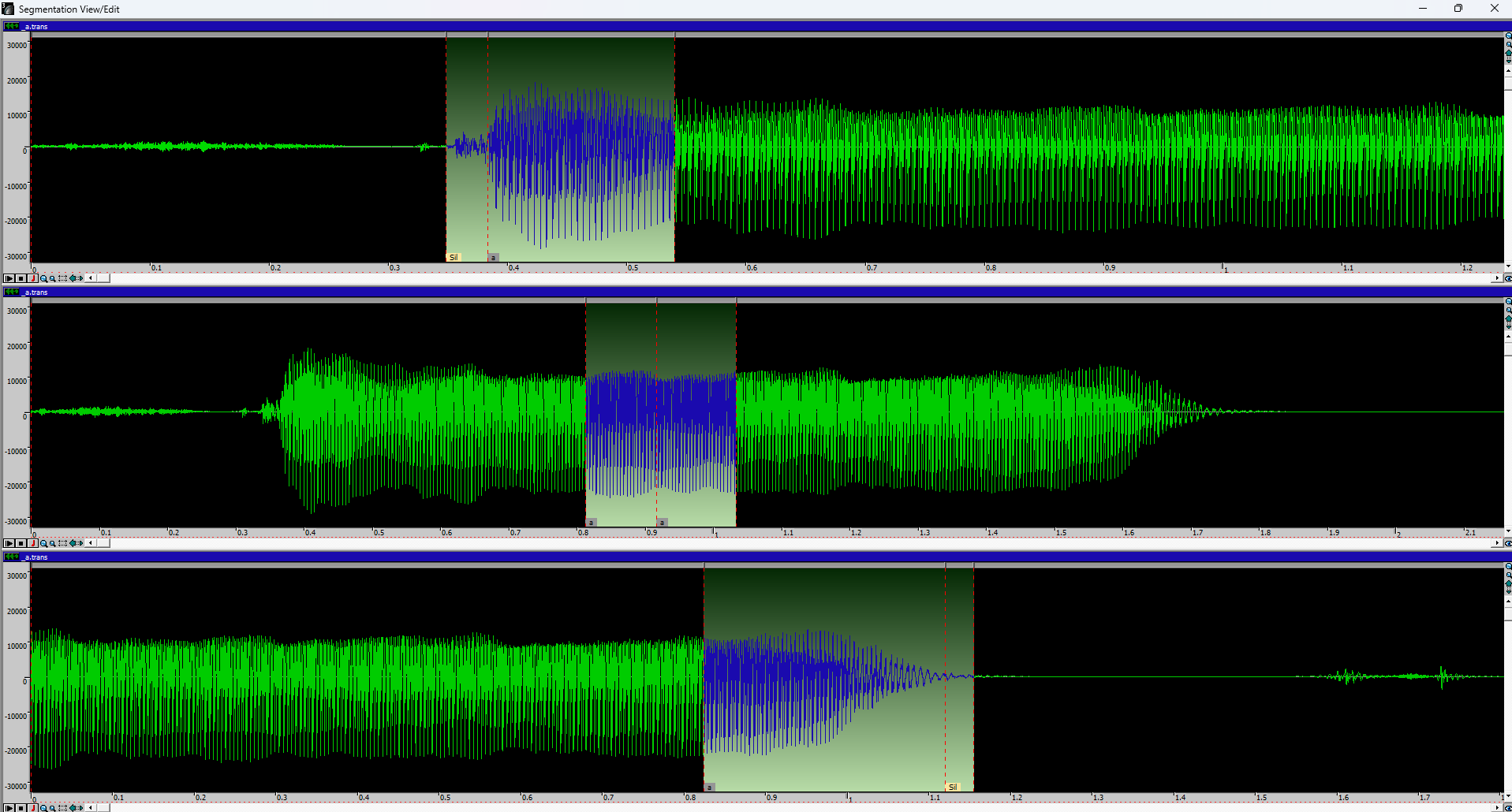
a i u e o被转换成一行文本Sil a i M e o Sil。- 在下方使用方括号,如
[a]、[i]等,划分出想要从该行提取的音频片段。下图是一个参考示例。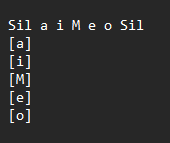
※ 关于步骤 5 和括号内音符的说明: 无需转录采样中的所有音素。您可以根据自己的喜好优化,只要确保包含所有需要的音素及其组合即可。强烈建议避免每个音高出现重复音符(例如:[b a] 在转录中出现两次)。
Vocaloid 使用“上下文”系统,允许某些音素仅在特定情况下出现,例如日语中不同的 N 音,或英语中的送气和不送气的辅音。以下列出了使用所有这些音素的示例。请务必根据这些示例进行转录。
※ 这些通常适用于日语。
| Stationary | 音素 | 使用 | 示例 |
|---|---|---|---|
| 是 | N\ | [a] [i] [u] [e] [o] [j] [w] [h] [h/] [p/] [p/’] [C] [s] [S] |
んお |
| 是 | n | [n] [t] [t’] [ts] [tS] [d] [d’] [dZ] [dz] [4] [4’] [Z] [z] [m] [m’] [J] [N] [N’] [N/] |
だん now |
| 是 | J | [J] | んにゃ |
| 是 | N | [N] [k] [g] | んか king |
| 是 | N’ | [N’] [k’] [g’] | んきゃ |
| 是 | m | [m] [p] [b] | せんぱい mom |
| 是 | m’ | [m’] [p’] [b’] | んみゃ |
| 否 | b’ d’ p\’ g’ C k’ m’ J p’ 4’ t’ | [i] | き |
| 否 | bh dh gh kh ph th | 送气英语辅音 | Baby dumb |
| 否 | b d g k p t | 不送气英语辅音 | Baby dumb |
| 否 | l0 | Light l | Lovely |
| 是 | l | Dark l | Dull |

如您所见,其中一些发音属于Stationary。不仅是日语,英语或您可能使用的任何其他语言也需要Stationary。如果您没有使用x-sampa转录,请务必小心,尽管规则基本相同。
※ 不要让 Vocaloid 自动填充语音过渡的空隙,这会导致编辑器中输出的声音非常生硬。缺失的转录意味着产生这样的空隙。为了获得最佳效果,请务必确保所有必要的语音过渡都有采样。
※ 为了更快捷地解决问题,您可以使用“资源”中列出的自动转录工具。使用时请注意,务必仔细检查并更正转录文本。
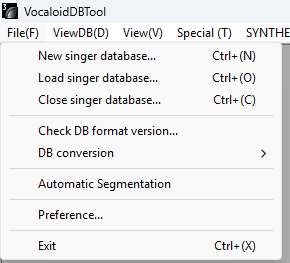
加载声库
您需要一个字典,可以从“资源”中下载。首先创建一个 .txt 文件,并将其命名为声库名称。请避免使用过长的名称和句点。
点击File(文件) -> New Singer Database(新建声库),加载您选择的字典与您声库名字命名的空.txt。系统将会自动生成与.txt同名的一个文件夹、一个.dat和一个.tree文件。,名称与您选择的名称一致。再次打开时,可从singer.inf所在的文件夹重新加载声库。
※ 无需担心忘记保存,DBTool 会实时保存编辑内容。
创建声库后,检查ViewDB -> stationary是否正常。下图显示它应该是什么样子。

音素下方会有X标记,其余部分基本为空。请记住,从左到右音调由低到高。添加录音后,它们会以小点的形式显示在这里。您可以点击它们进行查看、收听和编辑。随着您添加更多录音,X标记的数字也会增加。

分段与标注(制作声库)
要打开配置对话框,请点击File(文件)->Automatic Segmentation(自动分段),然后找到 wav+转录文件(子文件夹可以正确识别,但请确保所有转录文件都已准备就绪)。
※ 尽管名称为Automatic Database Creation Dialog(自动创建声库对话框),但配置过程实际上并非自动完成。
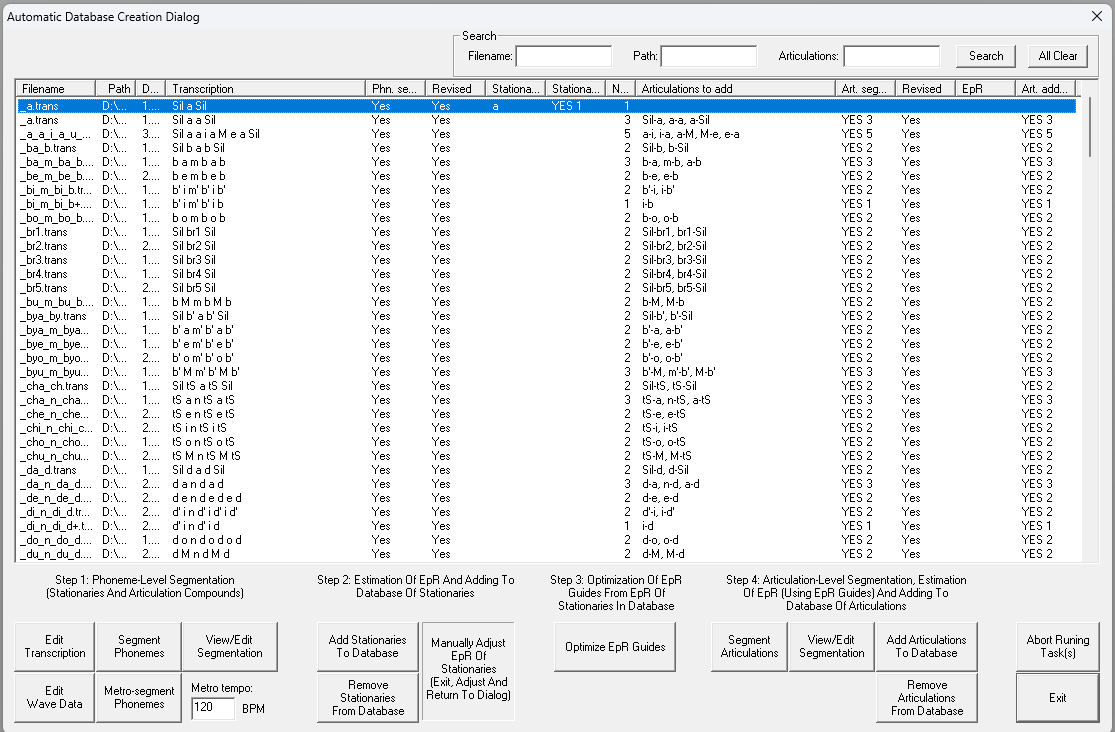

此对话框用于完成所有声库配置相关工作。您可以使用它来编辑转录文本、生成/编辑分段文件并将其添加到声库。
※ 提示:通过File(文件)->Preference(首选项),您可以添加外部音频编辑器(例如 Audacity、Sound Forge 等),然后通过声库创建对话框中的Edit Wave Data(编辑波形数据)打开该编辑器。
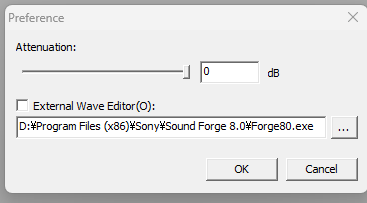
※ 步骤 3“优化 EPR 指南”非必需,可以忽略。
为了避免分段错误,您应始终确保转录文件中包含的所有音素也存在于字典 .txt 文件中。另请注意,Stationary和Articulation需要区分,且它们的配置方法也不同。
※ 请务必在查看分段结果之前进行音素分段,否则会导致 DBTool 崩溃。
※ 可以忽略Error-Forced Segmentation(错误强制分段),这种情况属于正常现象,几乎每次都会发生。
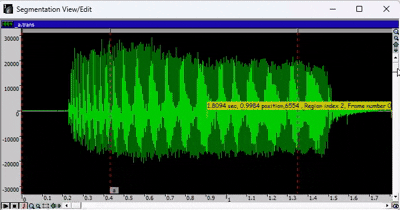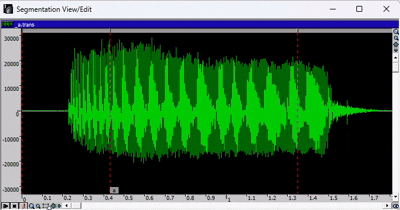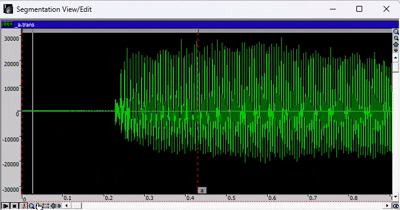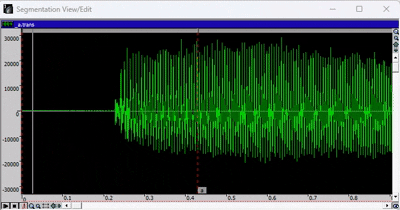
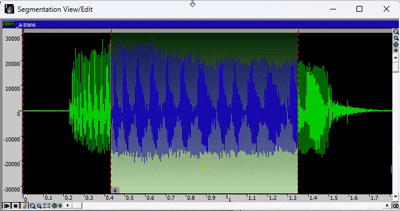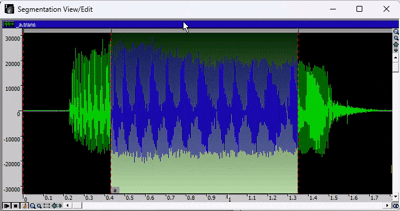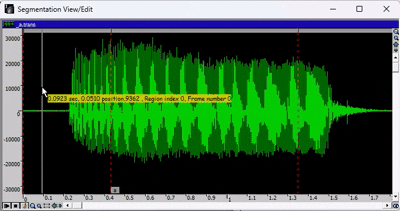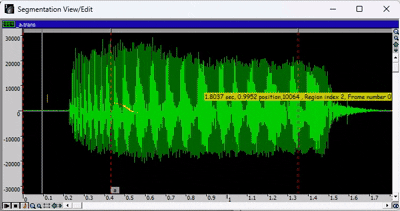
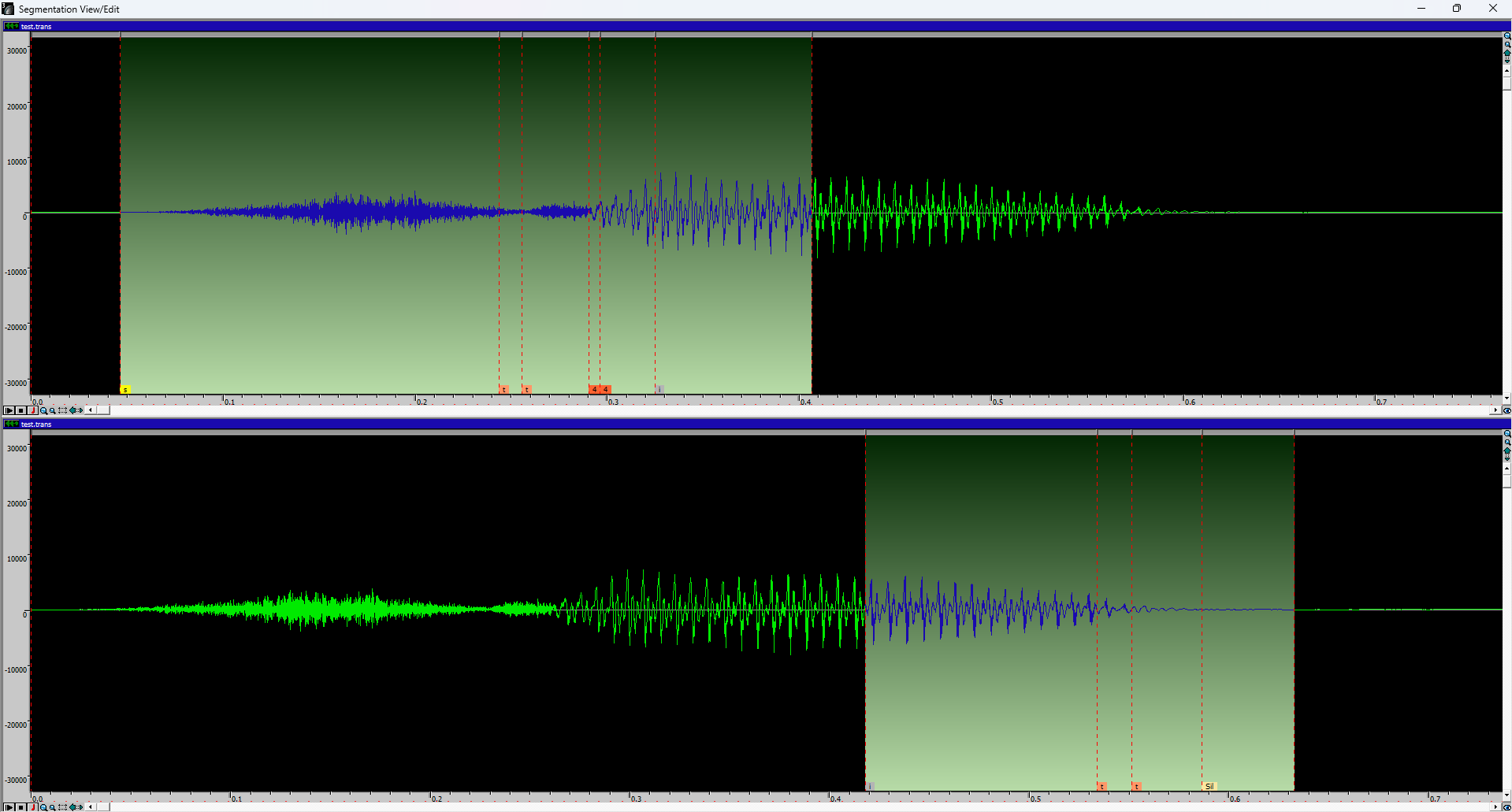
下图为分段查看/编辑窗口。
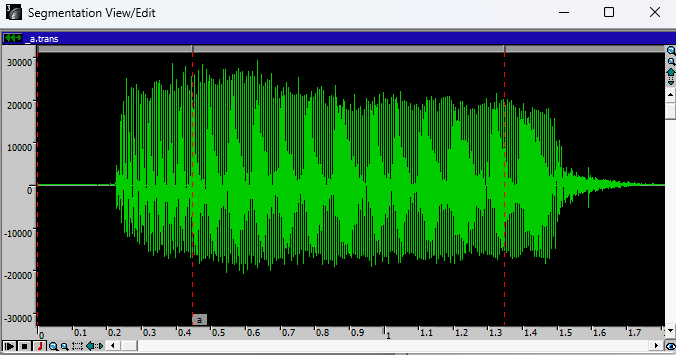
绿色波形代表录音,红色标记代表各个片段,小标签是与转录文件对应的音标。
- 要移动某个片段,您需要点击要编辑的片段之间的灰色横条,然后移动红色标记。

- 要放大或缩小,请使用窗口工具栏中的绿色箭头或放大镜图标。
- 要选择音频的特定区域,请按住 SHIFT 键并使用光标手动选择。要取消选择,请按住 SHIFT 键并单击。
- 要播放录音,请按空格键。如果已选择音频的某个区域,则只会播放所选部分。
- 完成分段后,关闭分段视图/编辑窗口。
Phn. Segmentation(音素分段)和Revised(已修改)下方的Yes表示工具已成功注册编辑。
总而言之,在这个制作流程中,您只需要精准和耐心。仓促的分段是不可取的,所以请务必预留充足的时间。
对于Stationary,工作流程如下:
- 分段音素;
- 查看/编辑分段结果 (※ 请勿跳过此步骤) ;
- 将
Stationary添加到声库。
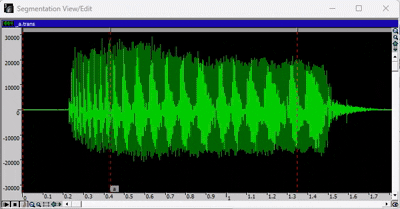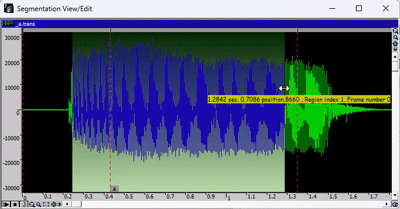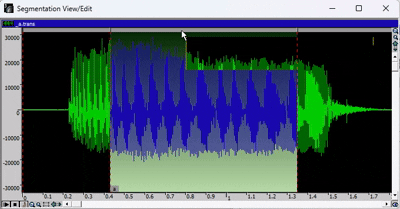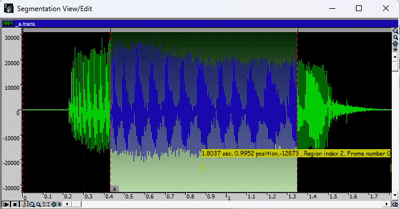
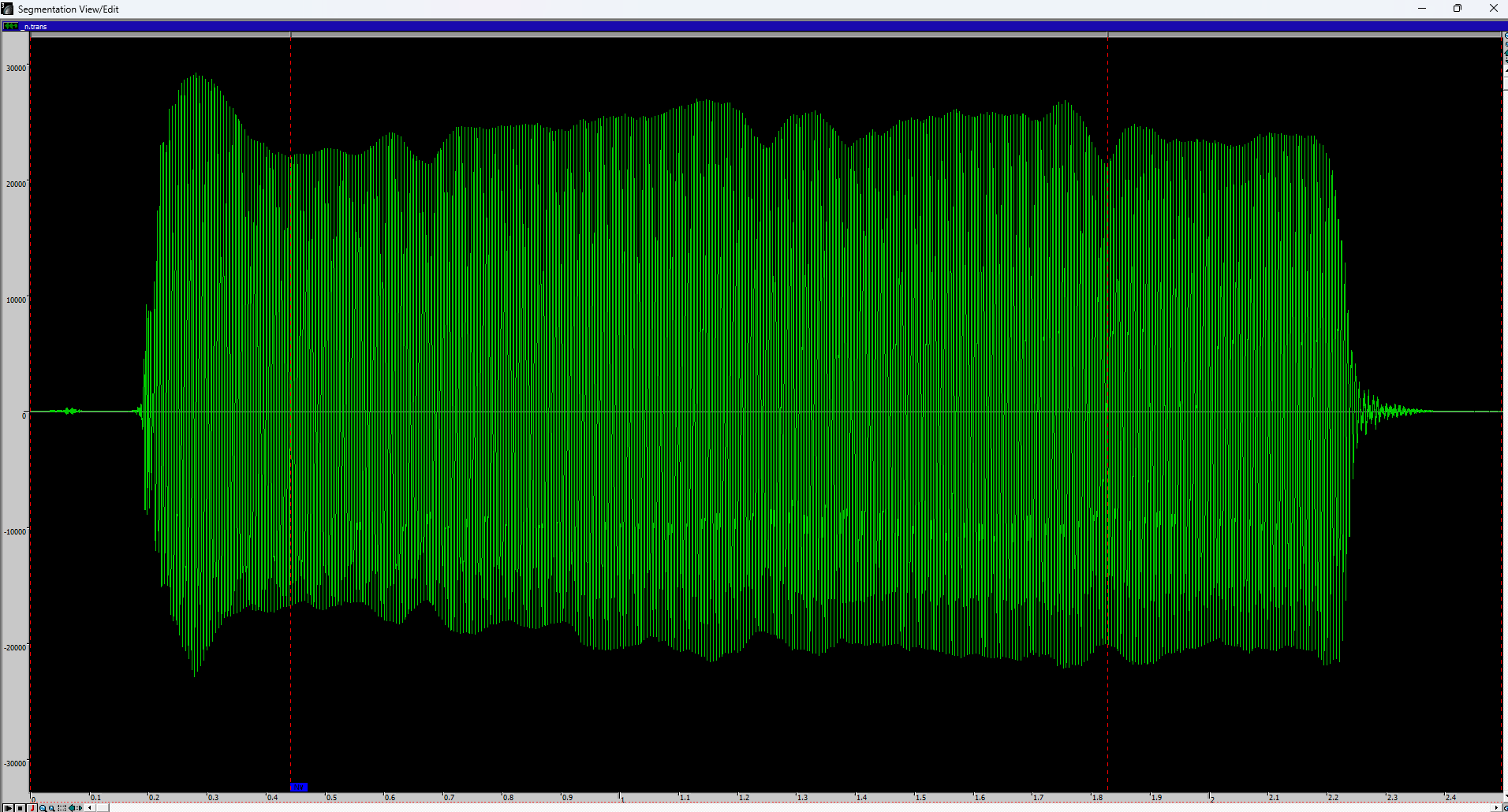
※ 配置Stationary时,应始终选择音频中最稳定的部分。同时,应确保所选部分长度适中。下图为示例。

对于Articulation,工作流程如下:
- 分段音素;
- 查看/编辑分段结果(※ 请勿跳过此步骤);
- 分段
Articulation; - 查看/编辑分段结果(※ 请勿跳过此步骤;可能需要进行修正/调整。请务必在添加到声库之前检查最终分段结果。)
- 将
Articulation添加到声库。
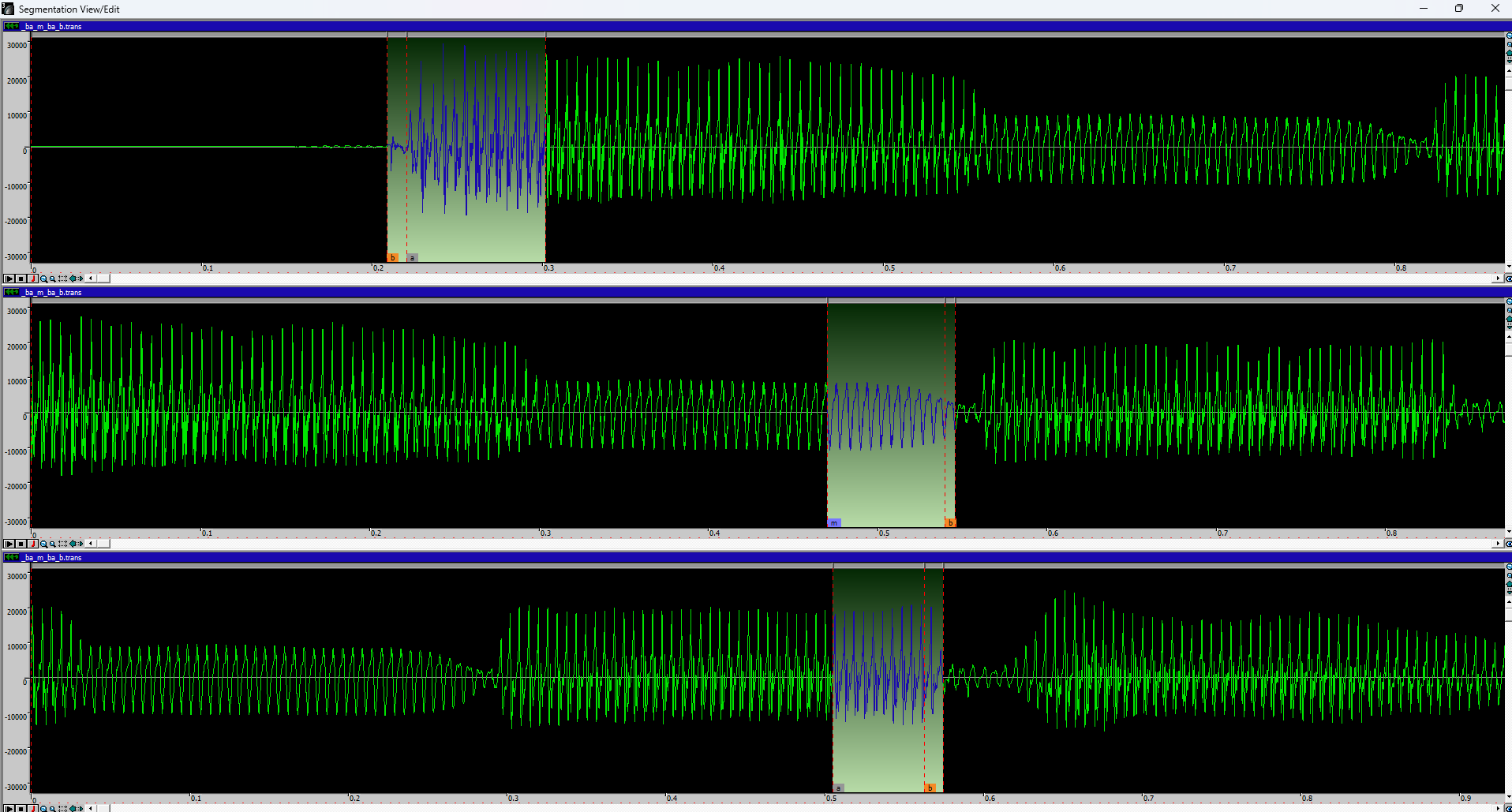
※ 注:在类似kya(きゃ)的音节中,y音与元音是分开的,因此请确保不要将ya音包含在k标记中。
以下是 DBTool 中不同数量转录显示的示例:

可显示的Articulation数量取决于转录文本中括号的数量。
※ 建议:您应始终优化转录文本,避免使用过多的括号。如果括号过多,Articulation分段窗口很容易过于拥挤,导致难以甚至无法查看转录。
以下是 DBTool 中各种Articulation转录的示例:
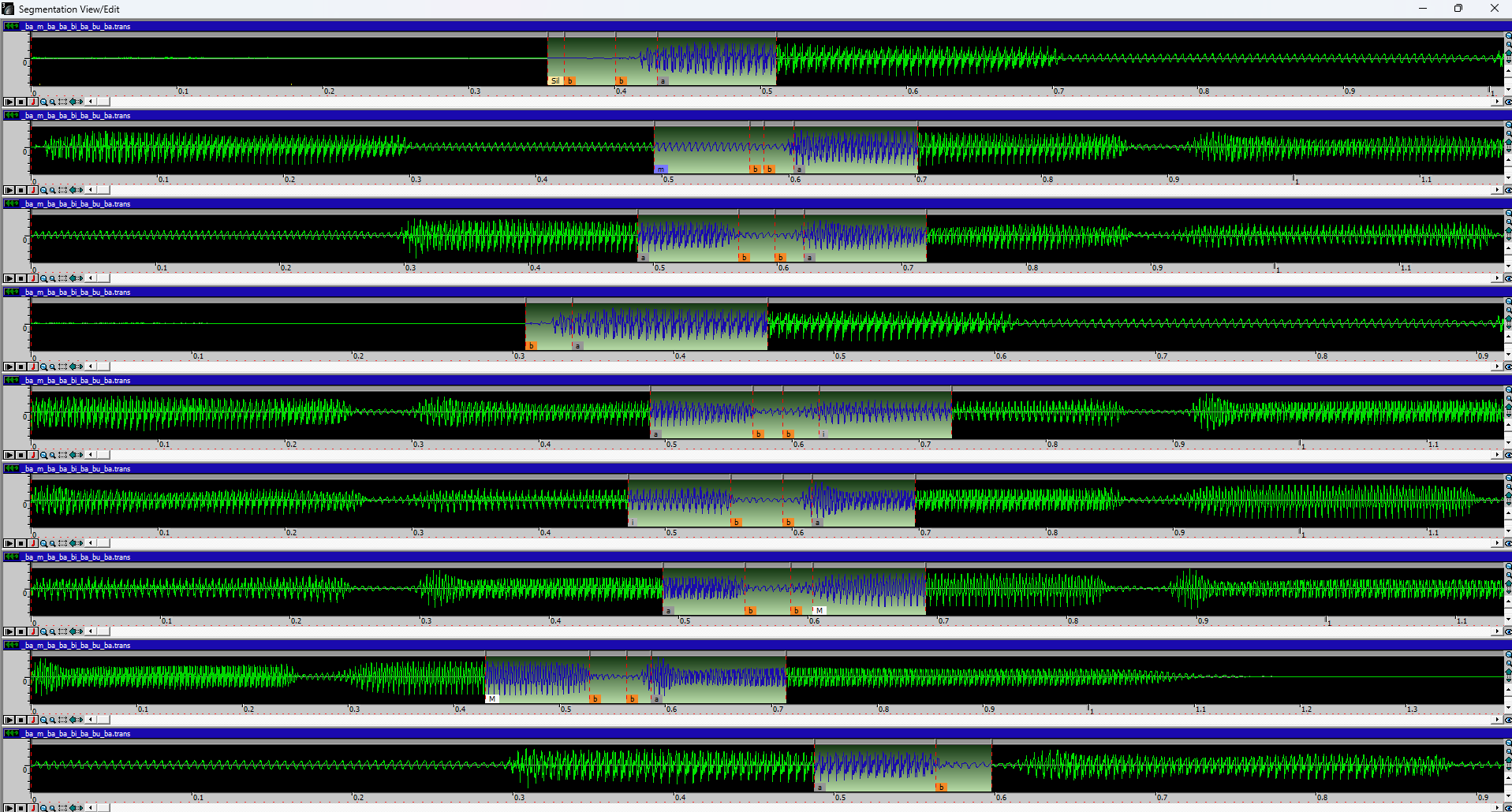
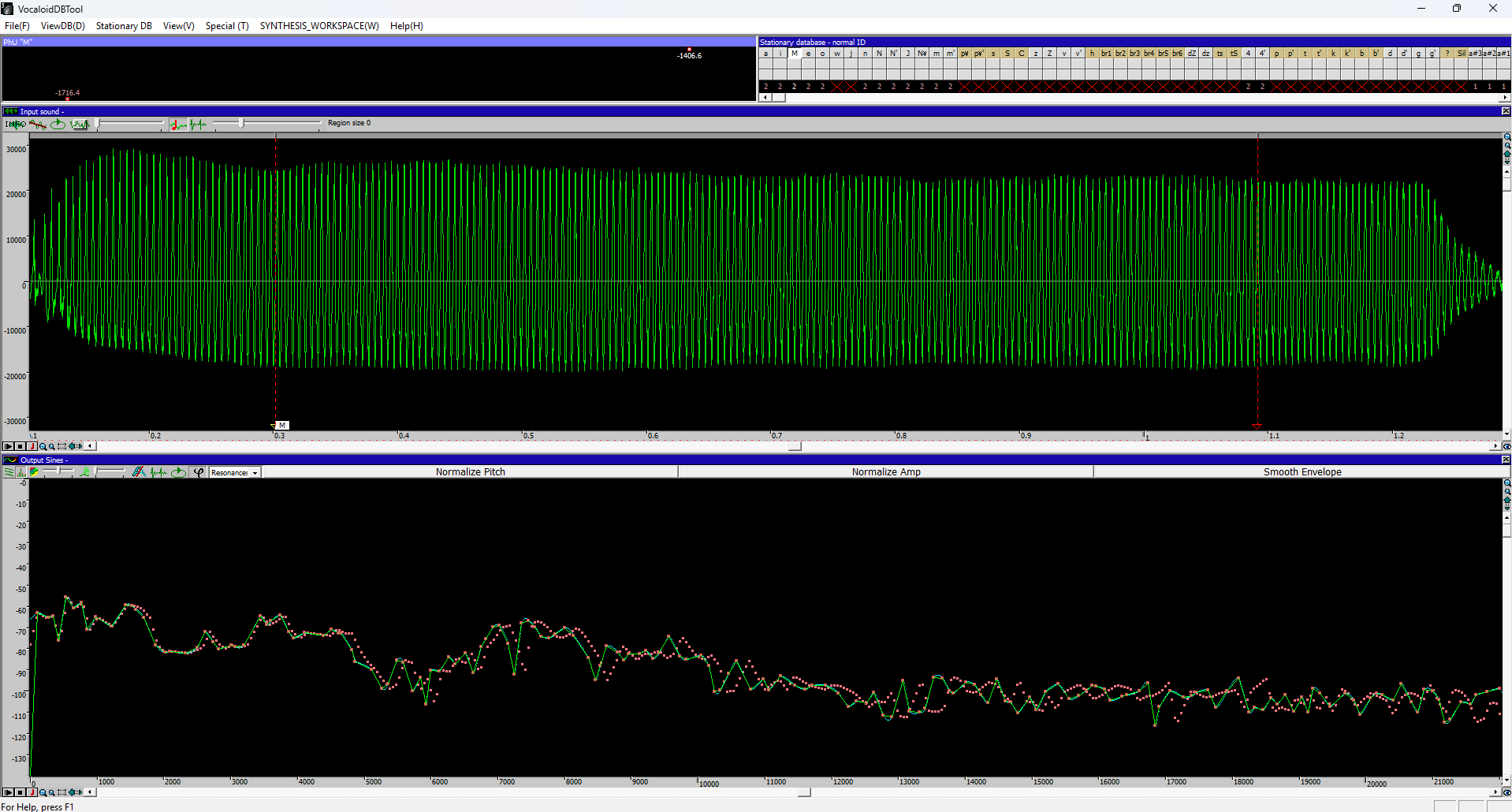
添加到声库后,它们将显示在 ViewDB 下。

点击红点将出现一个类似于分段对话框的菜单,您可以在此处对分段结果进行进一步调整或执行 f0 估计(通过View(视图)中的 AttPitchOutput)。
※ f0 估计类似于 UTAU .frq 文件的编辑。
请务必在通过DB Update(声库更新)进行更正后更新声库,否则应用程序将无法记录进度。
※ 关于 f0 估计:使用 CTRL + 单击来修正样本的音高(只需按所需方式绘制音高),使用 CTRL + D + 单击来删除音高。
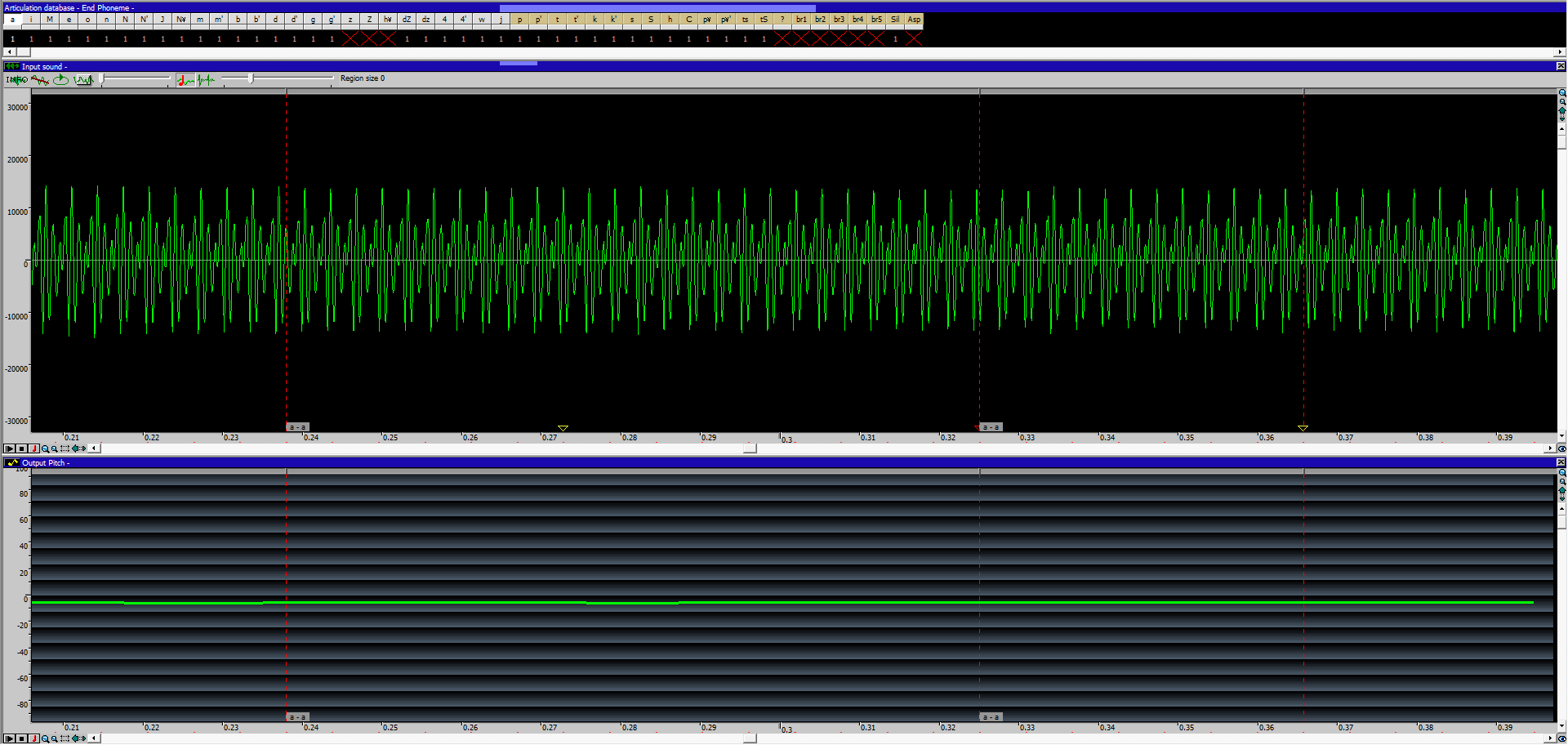
在任何情况下,进行任何编辑、更正或调整时,请务必先从声库中移除Stationary/Articulation。当然,完成后您可以再添加回去。否则可能会导致无法挽回的错误。

字典
如果词典缺少音素,或者音素分类错误,请转到Special(特殊) -> Change Phonetic Unit Group(更改音素单元组),并进行所有必要的更正。
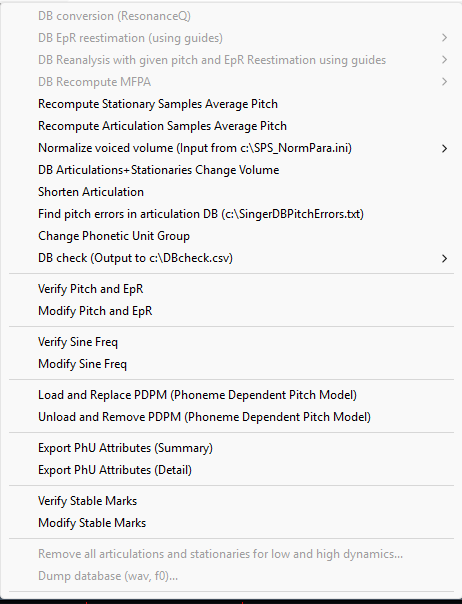
在此窗口中,您可以根据语音中的类型和用法添加音素。请注意,编辑后,DBTool 将关闭声库,您需要手动重新打开它。
实际上这方面几乎没有任何限制,所以请随意尝试各种不同的声音。
※ 可选/自定义 G2PA(音节无效)
好吧,也许您兴致勃勃。您想实现对一种尚未被原生支持的语言,甚至是音标系统的支持。
假设并非所有读者都了解 G2PA 或 X-Sampa 是什么,我会尽力涵盖本节您需要知道的所有内容。
什么是 G2PA?
如果您之前至少查看过一次 Vocaloid 文件,您很可能见过一些名为g2pa3_JPN.dll或g2pa3_ENG.dll的 .dll 文件。
简单来说,它们的作用是将您在编辑器中的输入转换为音标符号,以便声库能够识别音节。您有没有注意到,在音符中,あ旁边有一个用方括号括起来的[a]?这就是您输入的音标,这就是 G2PA 在发挥作用。它们本质上只是音素生成器。
什么是 X-Sampa?
首先要说明一点:X-Sampa并非Vocaloid独有的东西。
X-Sampa(Extended Speech Assessment Methods Phonetic Alphabet,拓展音标字母评估法)是一种使用ASCII字符表示国际音标的系统。初音未来并没有发明它。
Vocaloid使用X-Sampa作为其音标系统。因此通常情况下,在制作词典和G2PA时会用到它。尽管如此,只要方法正确并针对Vocaloid进行优化,完全可以实现您自己的音标系统。
那么,我该如何自己制作一个呢?又该如何让它在我的编辑器中运行呢?
“资源”包含一个模板。请搜索Custom G2PA Base。
.zip 文件包含一个 .dll 文件和一个 .ini 文件。两者都可以正常工作。Vocaloid 应该能够读取这两种文件。如果您熟悉如何编写和制作动态链接库,那就尽管使用吧。然而,并非每个人都知道如何实现这种“魔法”,因此我将解释更简单的方法,即编写 .ini 文件而不是 .dll 文件。
假设您已经准备好了一个词典以及一个配置了该词典的声库,实际上您只需要编写音节的音标即可。
例如:
[PhoneticArray]
a=a
ka=k a
ke=k e
……等等
这应该相当简单。您只需要耐心和时间。当然就像之前提到的,您需要一个预先制作好的词典来作为 G2PA 的基础。
把它导入编辑器可能会有点棘手。不过别担心,只要您小心谨慎别误操作,应该就没问题。
G2PA 编写完成后,前往 C:\Program Files (x86)\VOCALOID4\Editor 或 C:\Program Files (x86)\Vocaloid4FE(如果您使用的是 FE),然后添加音素。
默认情况下,Vocaloid 一次只能添加 5 个 G2PA,因为它在注册表中只有 5 个槽位。
要为您自己的音素器添加位置,您需要打开注册表编辑器,路径为:COMPUTER\HKEY_LOCAL_MACHINE\SOFTWARE\WOW6432Node\VOCALOID4\COMMON\LANGUAGE,如果您使用的是FE,则路径为:COMPUTER\HKEY_LOCAL_MACHINE\SOFTWARE\WOW6432Node\POCALOID4\COMMON\LANGUAGE。
然后,右键单击并创建一个新项(新建 -> 项)。名称完全可以任意设置,这里将其命名为“5”。
在您刚刚创建的项中,创建一个新的字符串值(新建 > 字符串值)。
双击该字符串,并将值名称更改为g2pa,将值数据更改为 G2PA 的名称。 (例如:g2pa4_CHS.dll、g2pa4_CHS.ini)
大功告成!自定义 G2PA 现在应该可以在 Vocaloid 中正常工作了。(特别感谢 ZouZouPowa 解决了这个问题!)
Vocaloid 4 开发版使用说明
※ 如果您好奇的话,此处无需保留 VIVI 的声库。
您需要设置开发版编辑器,然后填写声库路径。您可能已经知道,Vocaloid 必须至少安装一个声库才能运行,请记住这一点。与常规版本一样,编辑器启动也需要声库。
在 DB_Dev.ini 文件中,复制声库路径,并将BankSelect设置为您选择的语言。当您向 .ini 文件中添加声库条目时,VVoice、ProgramChange 和 ComponentID 的值将递增 1。DBPath 应设置为包含 singer.inf 文件的文件夹,DBName 应设置为 .tree 文件的路径。VVoiceName 可以是任何名称,通常就是声库的名字。
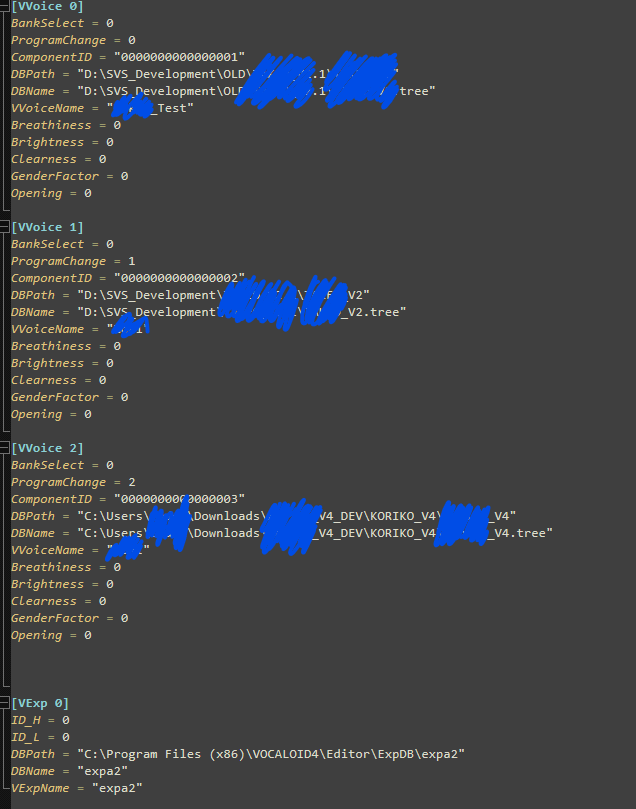
此版本的 Vocaloid 编辑器仅用于测试目的,因此存在一些限制,例如不支持 XSY 交叉合成等。
SYNTHESIS_WORKSPACE(W)
SYNTHESIS_WORKSPACE(合成工作区)是 DBTool 众多实用功能之一。它允许您直接查看 Vocaloid 编辑器如何使用声库。要访问此功能,只需从开发编辑器渲染一个序列,并将其与 .msd 文件一起保存即可。
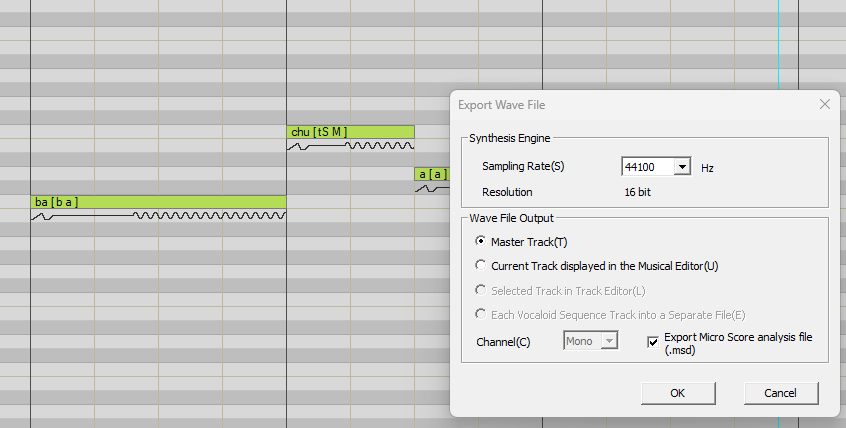
返回 DBTool;确保声库已加载,然后单击 SYNTHESIS_WORKSPACE。

加载音频文件。(.msd 文件将自动加载。)
现在您可以直接查看声库内部发生的情况了。
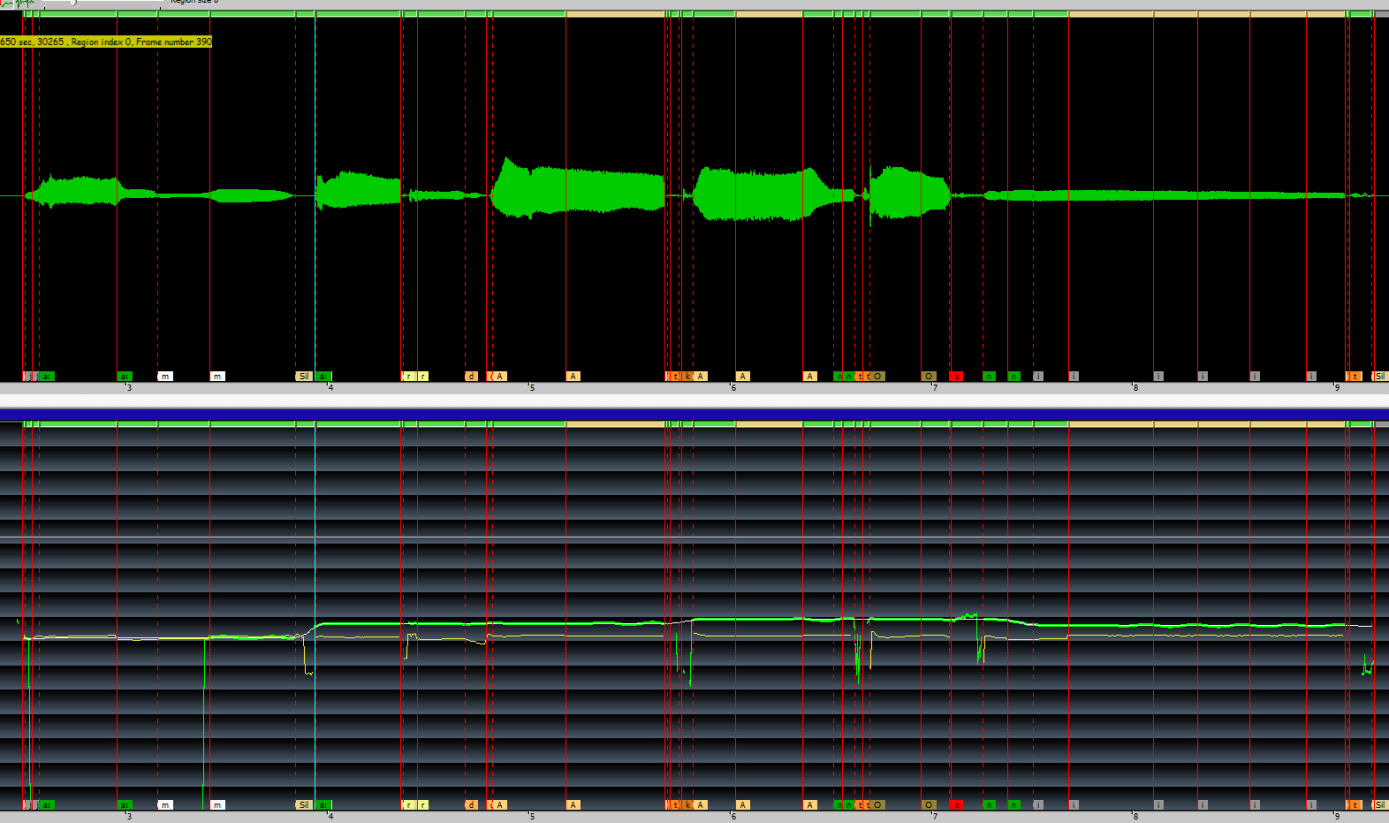
记住这一点很有帮助,因为它可以帮助您追踪诸如语音或音调缺陷之类的问题。
打包声库及Component ID
需要什么?
- 您配置完整的开发声库
- Python 3.10
- Yuukawa Hiroshi 的 ddbtools;它也有图形界面版本和
.exe文件(资源)
*不需要使用 conda。
以下将解释如何使用原始脚本及其图形界面。
下载所有文件并设置好 Python 后,请在终端中使用以下命令安装依赖项:
cd [ddbtools 目录路径]
pip install -r requirements.txt*
*注意:依赖项安装可能需要一些时间,尤其是在您第一次设置 Python 环境时。
接下来,您需要打包声库。请记住,所有内容都必须正确无误,所有数据都必须添加到声库中,并且所有内容都必须配置好。请勿使用不完整的声库。如果您只想进行快速测试,则应删除未完成的条目或使用 V4 开发版编辑器。
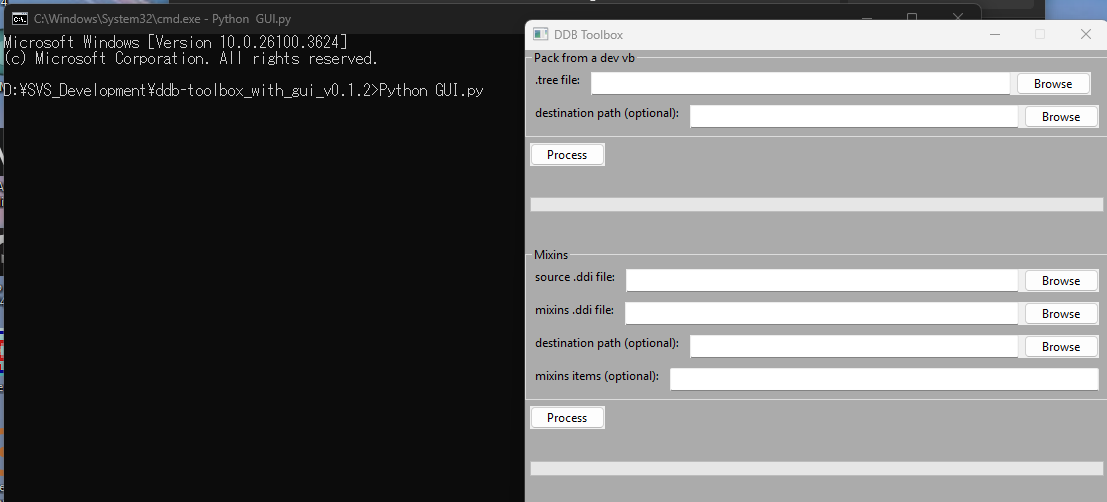
如果您使用的是GUI,请运行以下命令:
cd [ddbtools 目录路径]
python GUI.py
输入第二个命令后,GUI应该会立即出现。链接声库 .tree 文件,然后点击Process(处理)。根据声库的大小,这可能需要一些时间。只需让它在后台运行即可。完成后,该工具会通知您。
如果您使用的是 pack_ddb.py 脚本,请运行以下命令:
cd [ddbtools 目录路径]
python pack_ddb.py --src_path "[声库 .tree 文件路径]" --dst_path "[输出目录,完成后 .ddb 和 .ddi 文件将出现在此处]"
再次提醒,让它在后台运行。
马上就要成功了,但仅凭 .ddb 和 .ddi 文件是无法使用声库的。您还需要 .vvd 文件和组件 ID。
那么,这些是什么呢?
.vvd 文件包含声库的相关信息,例如声库名称、Component ID、所属公司等等。(简而言之,就是元数据)
Component ID 是分配给每个声库的唯一 ID。务必确保声库 ID 与其他声库的 ID 不重叠。
如何生成 CompID?
最简单生成 CompID 的方法是直接使用 VVDEditor 工具。但是建议不要这样做,或者至少不要总是这样做。
VVDEditor 的 ID 列表有限,只有大约 20 个(或更少),因此 ID 存在重叠的风险,而这是不希望发生的。
所以,理想情况下应该手动编写 CompID。
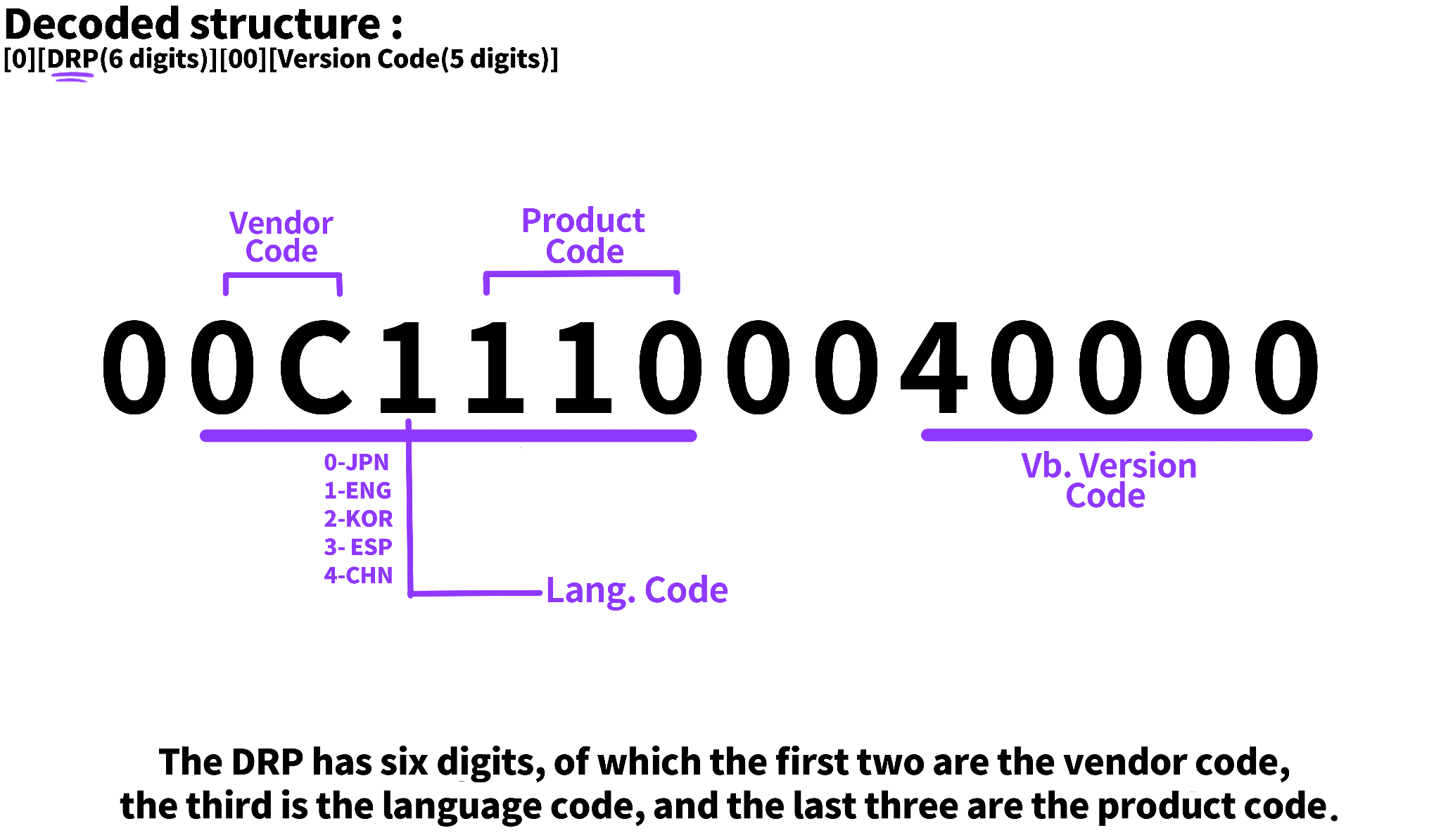
VOCALOID Component ID 是由14位数字组成的字符串,每一位都代表声库的不同信息,例如厂商编码、产品编码、语言编码和版本编码。※ 请参考下图以获得更清晰的理解。
写好ID后,需要将其转换成标准的16位编码。为此,您需要使用转换格式的工具。eemorph 的 VOCALOID2 Keygen 可以做到这一点,所以我们将用它来举例说明。
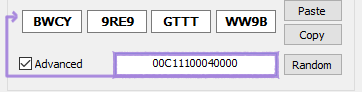
只需启用Advanced(高级)选项,输入原始字符串,工具即可自动完成编码工作。现在您可以复制生成的 ID 并将其用于声库。※ 请务必确保所有信息填写正确,否则可能会导致编码错误或声库在编辑器中出现故障。
如何创建 .vvd 文件?
首先访问VVD 编辑器。如果您还没有 CompID,请点击?生成一个,或者使用您自己的 CompID。该网站默认仅支持中文和日文,但您也可以创建其他语言的声库。
获得 CompID 后,返回首页并将其粘贴到声库 CompID栏中。同时,请确保在声库名称栏中输入您声库的姓名。
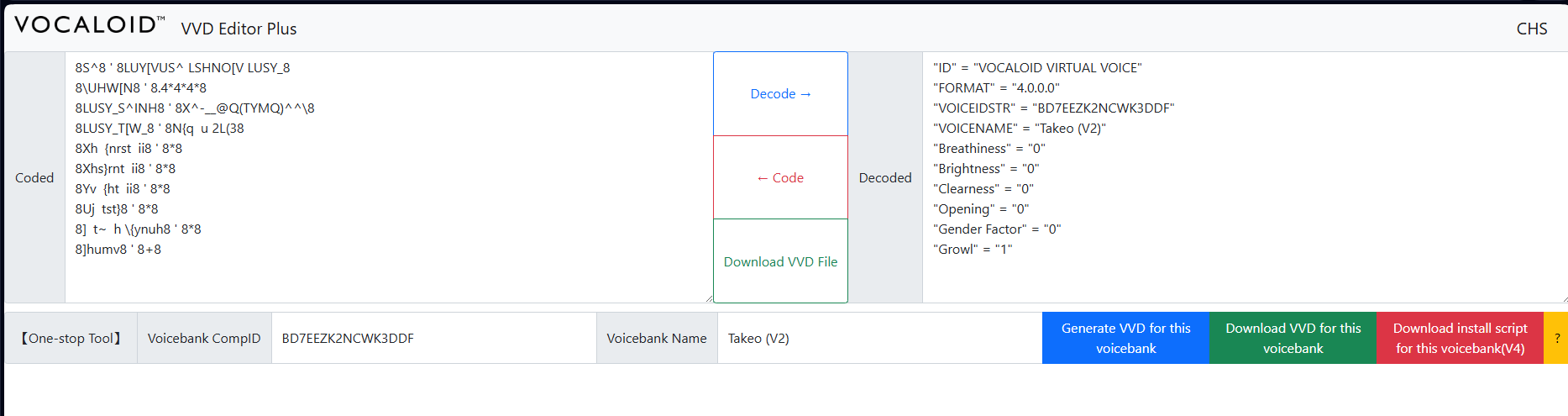
供您参考:
您可以更改ID,但并非必须。
FORMAT是声库版本。
VOICESTR是CompID。
其余均为参数。*注:如果您正在创建V3数据库,请务必完全移除Growl。
如果您进行了任何编辑,请务必点击加密。
完成后,点击下载声库VVD,也可以通过下载安装脚本生成.bat安装脚本。虽然这不是必须的,但并非强制要求。(需允许网站下载多个文件)
最后,准备最终的文件夹
创建一个文件夹,并将.ddb、.ddi和.vvd文件放入其中,文件夹名称为声库CompID。请务必确保所有文件名称相同,否则编辑器可能无法读取声库信息。(您也可以稍后更改所有文件名)
※ 可选,V4 的 Mixins/Growl 打包
需要什么?
- 一个已打包的声库
- 一个带有 Growl 的 V4 声库(例如 V4 Flower、Cyber Songman 等)
- ddbtools(链接见上文)
无论是 GUI 界面还是脚本,其操作流程都与打包流程非常相似,因此不再赘述。
如果您使用GUI:
- Source .ddi 文件是您要从中提取咆哮声的 V4 声库文件
- Mixins .ddi 文件是“目标”.ddi 文件,也就是声库文件
如果您使用 mixins_ddb.py:
cd [ddbtools 目录路径]
python mixins_ddb.py --src_path "[声库 .ddi 文件路径]" --mixins_path "[您要从中提取咆哮声的 .ddi 文件路径]" --dst_path "[输出目录]"
※ 请勿为同一个声库创建多个 CompID!在重新打包的情况下,您可以重复使用同一个 CompID。
导入Vocaloid编辑器
将打包好的声库(如果有的话,还需要安装程序)后,您可以使用Vocaloid 4 FE Plus的Voice Management将其加载到软件中。启动软件,通过File import(文件导入)找到声库,并可选择解锁XSY。
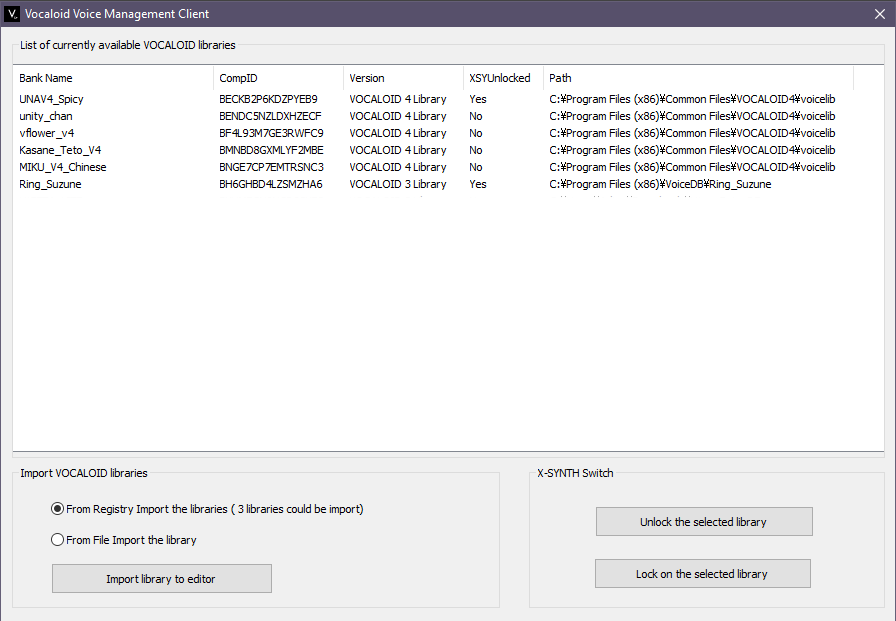
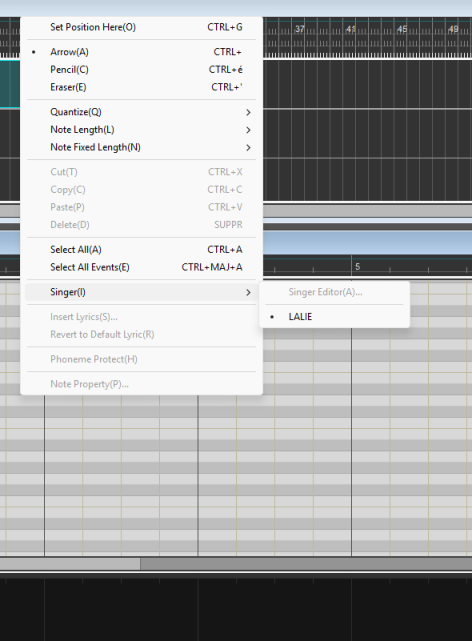
使用当前歌手属性,您可以设置默认歌手、创建 XSY 预设等等。
将声库导入 Vocaloid5/6 编辑器非常简单,只需以管理员身份运行通过 VVD Editor Plus 生成的 .bat 安装程序,运行一次 Vocareg 即可(这是针对 FE 库的情况,而“正版”数据库的工作流程则大不相同)。
这样声库也会出现在 Tunelab 中,使其完全可用。
添加Vocaloid 5/6的图像
- 您需要查看以下路径:
C:\Program Files\Common Files\VOCALOID5\Resource\Voice
C:\Program Files\Common Files\VOCALOID6\Resource\Voice - 在上述任一路径下,创建一个名为“声库的 compID”的文件夹。
- 在新建的文件夹中,添加一个名为 setup.bmp 的图片;图片尺寸需为 600x324。
**务必记住要保持设置 bmp 的正确尺寸!**

资源
请注意误报,所有列出的工具均安全可靠且经过测试。请确保已安装 Python 3.10。*最好使用 Python 3.10,不要使用其他版本。某些工具已知对其他版本存在兼容性问题。
以上资源以及更多其他资源,您也可以在上方链接的 Discord 服务器中找到。
- EpR 文档扩展程序(来自 razer_rhela)
- VVD Editor Plus(来自 UselessBug 和 atonyxu)(允许您为声库生成 VVD 文件、安装和卸载脚本。当您需要将声库打包以便在其他编辑器中使用时,此工具非常有用。)
- DDB Tools(来自 Yuukawa Hiroshi)(用于将声库打包成 V3-V6 可以使用的可读格式)
- DDB Tools GUI(来自 UselessBug 和 Yuukawa Hiroshi)(一种更简便的声库打包方式。)
- Vocaloid 自定义语言 G2PA 表格(来自 ZouZouPowa)
- Vocaloid 自定义语言 G2PA 基础文件(来自 Yanwu Project)
译注:连接失效
- Phn_Seg_edit(来自 H5X2) Phn_Seg.py 的一个分支;生成类似 moresampler 的基础文件。您需要 wav 文件和转录文件。
- Lab to seg(来自 Rozea/Kori)
- Melodyne 用于编辑或校正采样音高(如有需要)。
旧版文档中的资源:
- VocaloidDBTool3
译注:此资源可在bilibili中找到
- SMSTools2
译注:此资源可在bilibili中找到
ViVi + VocaDev(无需保留Vivi)译注:此资源可在vocakey中找到 链接仍有效,但已不再需要
- Vocaloid 4 FE Plus(包含一个无需安装即可注册声库的软件,但声库仅在Vocaloid 4 FE Plus中显示)
译注:此资源可在vocakey中找到
- Piapro V4X(包含一个无需安装即可注册声库的软件,但声库仅在Piapro中显示)
译注:此资源可在vocakey中找到
- Deepvocal 测试一下音域吧!!
- Canned Bread’s Swiss Army Knife(创建空白的
.trans文件,以及将.oto文件转换为.seq文件) - QuickBMS
- VVD Editor Plus(生成VVD文件、安装和卸载脚本。将声库打包以供其他编辑器使用时非常有用)
译注:文内链接均为译者fork版本,更新部分V4英语CompID。
- DDB Tools(将声库打包成V3~V6都可以使用的格式。需自备含有咆哮声ddb和ddi文件,我们没法直接提供。可用VY1或Flower的,CYBER SONGMAN是最原始的咆哮声源。)
- Colab版(已更新为使用Github存储库)
译注:搬运链接,请自行在本地Jupyter或国内Colab平替中使用
- DDB Tools GUI(From UselessBug)(更简单的打包工具,需要Python。在cmd中执行
python -m pip install -r requirements.txt以安装。安装后,执行python GUI.py即可启动。) - oto2seg(将UTAU oto转换为Vocaloid文件。它会切割样本,确保已安装ffmpeg和pydub,将其放在同一文件夹中。该工具并不完美,请确保样本清晰。仍需自备
Stationary和C/V Sil。mm'NN'和J也不会自动生成。它会跳过不常见的日语组合,如Hu(ほぅ)、Fu(ふぅ)、Wu(うぅ)和Yi(いぃ)。) - 自定义字典模板(不像其他字典那样正常工作。使用时,需替换Vocaloid目录中的一个字典文件。确保文件名称相同。不要删除被替换的字典,以便正常使用。)
- GUMI英语录音表(非模板)(若能自行转换,您将获得模板)
译注:搬运链接
- 日语CVVC/VCV录音表+转录文件(From Enlilgen)
- 日语CVVC录音表+转录文件(From Inochi-P)
- 基于单词的日语录音表(From Ko Ko) 像UTAU那样录制。每个音节对应一个音拍。(注意
N算独立的音拍。)虽不完美,但这是一个很好的基础。采样需要复制粘贴。 - 基于单词的英语录音表(From Canned Bread/luciozundiezz) 像UTAU那样录制,每个音阶对应一个音拍。(参考GUMI的录音表决定要复制哪些样本)虽不完美,但这是一个很好的基础。采样需要复制粘贴。
- 基于单词的西班牙语录音表PDF(From AnotherNN) 虽不完美,但已精简。
- Vocaloid2Keygen
- 字典(From daigasso)
- Melodyne如果需要的话,编辑或校正样本的音高!
- Takeo V2(示例CVVC声库+开发文件) (支持咆哮声,已更新为更响亮、更清晰的采样)提供以便于学习并解答关于应该做什么和不应该做什么的疑问。遵循
readme文件即可尽情地分析它!进行各种实验,尽情发挥,把它作为开发您自己的录音列表或声库的基础。 - Takeo V4 HARD(示例VCV/CVVC声库+开发文件)规则同V2声库,您可以交叉合成两个声库。
译文
本文档的翻译版
以下译文由其他用户提供,因此可能已过时或有所更改。
感谢贡献!
